Data Consistency Primer
Облачные приложения обычно используют данные, которые распределяются между хранилищами данных. Управление и поддержание согласованности данных в этой среде может стать критическим аспектом системы, особенно с точки зрения проблем параллелизма и доступности, которые могут возникнуть. Вам часто приходится торговать сильной согласованностью для доступности. Это означает, что вам может потребоваться разработать некоторые аспекты ваших решений вокруг понятия конечной согласованности и принять, что данные, которые ваши приложения используют, могут быть несовместимыми все время.
Управление согласованностью данных
Каждое веб-приложение и служба используют данные. Эти данные часто необходимы, чтобы помочь пользователям и организациям принимать бизнес-решения, и поэтому может быть важно, чтобы эти данные точно отображали самую актуальную имеющуюся информацию и что она последовательна. Согласованность данных подразумевает, что все экземпляры приложения представлены с одинаковым набором значений данных все время. Такой подход иногда называют сильной согласованностью данных.
В мире реляционных баз данных непротиворечивость часто реализуется транзакционными моделями, использующими блокировки для предотвращения одновременного изменения одновременных экземпляров приложения. В сильно согласованной системе блокировки также блокируют параллельные запросы для запроса данных, но многие реляционные базы данных позволяют приложению смягчать это правило и предоставлять доступ к копии данных, которые отражают состояние, в котором оно находилось до начала обновления. Многие приложения, которые хранят данные в нереляционных базах данных, плоских файлах или других структурах, следуют аналогичной стратегии, известной как пессимистическая блокировка. Экземпляр приложения блокирует данные во время его изменения, а затем освобождает блокировку после завершения обновления.
В современном облачном приложении данные, вероятно, будут разделены между хранилищами данных, размещенными на разных сайтах, некоторые из которых могут быть распределены по широкой географической карте. Это может произойти по целому ряду причин: улучшить масштабируемость путем балансировки нагрузки на нескольких компьютерах, улучшить время отклика путем совместного размещения данных рядом с пользователями и службами, которые обращаются к нему, или улучшить доступность путем репликации данных на разных сайтах.
Поддержание согласованности данных в распределенных хранилищах данных может стать серьезной проблемой. Проблема в том, что такие стратегии, как сериализация и блокировка, хорошо работают, если все экземпляры приложений используют одно и то же хранилище данных, и приложение разработано таким образом, чтобы блокировки были очень короткими. Однако, если данные разделены или реплицируются в разных хранилищах данных, блокирование и сериализация доступа к данным для обеспечения согласованности могут стать дорогостоящими служебными данными, которые влияют на пропускную способность, время отклика и масштабируемость системы. Поэтому большинство современных распределенных приложений не блокируют данные, которые они модифицируют, и они принимают более расслабленный подход к последовательности, известный как возможная согласованность.
 .gif") Заметка: Заметка: |
|---|
| Для получения информации о распространении данных на удаленных местах, совместного размещения данных и репликации и синхронизации данных см Partitioning Наведение данных и репликации данных и синхронизации Guidance . |
В следующих разделах представлена дополнительная информация о сильной согласованности и возможной согласованности, а также о проблемах, которые окружают эти разные подходы к поддержанию согласованности данных в распределенной среде, такой как облако.
Сильная непротиворечивость
В сильной модели согласованности все изменения являются атомарными. Если транзакция обновляет несколько элементов данных, транзакция не может быть завершена до тех пор, пока все изменения не будут выполнены успешно (или в случае сбоя), все они были отменены. В промежутке между началом и завершением транзакции другие параллельные транзакции могут не иметь доступа к какой-либо из данных, которые были изменены; они будут заблокированы. Если данные реплицируются, транзакция, которая реализует сильную согласованность, может не дозвониться до тех пор, пока каждая копия каждого измененного элемента не будет успешно обновлена.
Целью модели сильной согласованности является минимизация вероятности того, что экземпляр приложения может быть представлен с несогласованным представлением данных. Стоимость реализации этой модели — это влияние, которое она оказывает на доступность, производительность и масштабируемость полученного решения. В распределенной среде, если хранилища данных, содержащие данные, затронутые транзакцией, географически удалены друг от друга, задержка в сети может отрицательно повлиять на производительность таких транзакций и привести к одновременному доступу к заблокированным данным в течение длительного периода времени. Если сбой в сети делает одно или несколько хранилищ данных недоступными во время транзакции, приложение, обновляющее данные в системе, которая реализует сильную согласованность, может быть заблокировано до тех пор, пока каждое хранилище данных не станет доступно снова.
Кроме того, в распределенной среде, такой как облако, реализация сильной согласованности не допускает типов сбоев, которые могут возникнуть. Например, может быть невозможно отменить транзакцию и освободить ресурсы, которые она хранит, если компонент, участвующий в транзакции, перестает отвечать из-за длительного простоя сети. В этом случае необходимо будет разрешить ситуацию с помощью других средств, таких как ручная настройка данных.
| Заметка: |
|---|
| Многие формы хранения данных, используемые облачными приложениями, не поддерживают сильную согласованность в разных хранилищах данных. Например, при использовании Microsoft Azure Storage невозможно реализовать транзакции, которые охватывают несколько хранилищ blob или таблиц. |
В облачном приложении вы должны реализовать сильную согласованность только там, где это абсолютно необходимо. Например, если приложение обновляет несколько элементов, расположенных в одном хранилище данных, преимущества сильной согласованности могут перевесить недостатки, поскольку данные, вероятно, будут заблокированы только в течение очень короткого периода времени. Однако, если элементы, которые будут обновляться, будут распределены по сети, может быть более уместно ослабить требование для сильной согласованности.
В системе, которая реализует сильную согласованность, но также реплицирует данные в удаленные местоположения, может быть целесообразно распространять изменения в репликах за пределами строго согласованной транзакции. Некоторый уровень кратковременной несогласованности почти неизбежен, в то время как реплики обновляются, но данные в конечном итоге становятся последовательными после завершения синхронизации между репликами. Для получения дополнительной информации см. Руководство по репликации данных и синхронизации .
Альтернативный подход для поддержания сильной согласованности между реплицированными данными, которые часто реализуются с помощью масштабируемых баз данных NoSQL, заключается в использовании кворумов чтения и записи и управления версиями. Такой подход позволяет избежать блокировки данных за счет некоторой дополнительной сложности в процессах чтения и записи данных. Для получения дополнительной информации см. Раздел «Улучшение согласованности» в главе 1 «Хранение данных для современных высокопроизводительных бизнес-приложений» руководства. Доступ к данным для высокомасштабируемых решений: использование SQL, NoSQL и многоугольника на MSDN.
Конечная согласованность
Возможная согласованность — скорее более прагматичный подход к согласованности данных. Во многих случаях сильная согласованность на самом деле не требуется, поскольку в течение некоторого времени вся работа, выполняемая транзакцией, завершается или откатывается, и никакие обновления не теряются. В модели возможной согласованности операции обновления данных, охватывающие несколько сайтов, могут пульсировать через различные хранилища данных в свое время, не блокируя одновременные экземпляры приложений, которые обращаются к тем же данным.
Один из дисков для возможной согласованности состоит в том, что распределенные хранилища данных подчиняются теореме CAP. Эта теорема гласит, что распределенная система может реализовать только две из трех функций (согласованность, доступность и разделяемость) в любой момент времени. На практике это означает, что вы можете:
- Обеспечить согласованное представление распределенных ( секционированных ) данных за счет блокировки доступа к этим данным, в то время как любые несоответствия разрешаются. Это может занять неопределенное время, особенно в системах с высокой степенью задержки или если сетевой сбой приводит к потере подключения к одному или нескольким разделам.
- Обеспечьте немедленный доступ к данным с учетом того, что они не соответствуют друг другу. Традиционные системы управления базами данных сосредоточены на обеспечении сильной согласованности, тогда как облачные решения, использующие секционированные хранилища данных, обычно мотивируются обеспечением большей доступности и, следовательно, более ориентированы на возможную согласованность.
| Заметка: |
|---|
| Вероятная согласованность вряд ли будет указана как явное требование распределенной системы. Вместо этого это часто является результатом внедрения системы, которая должна обладать масштабируемостью и высокой доступностью, что исключает наиболее распространенные стратегии обеспечения сильной согласованности. |
Экземпляр приложения может видеть представление элемента данных, на которое воздействует операция в состоянии, в котором он находится, пока операция находится в полете, и это представление может быть временно непоследовательным. В зависимости от требований системы разработчику может потребоваться разработать приложения для обнаружения и обработки таких несоответствий, а затем предпринять шаги для их устранения, если это необходимо.
Конечная согласованность также влияет на согласованность данных при использовании кеширования. Если данные в удаленном хранилище данных меняются, все копии, кэшированные приложениями, скорее всего, устарели. Настройка политики истечения срока действия кэша, которая предотвращает чрезмерное устаревание кэшированных данных и использование таких методов, как шаблон Cache Aside , может помочь уменьшить вероятность возникновения несоответствий. Однако эти подходы вряд ли полностью устранят несоответствия в кэшированных данных, и важно, чтобы приложения, использующие кеширование в качестве стратегии оптимизации, могли справляться с этими несоответствиями.
Следует иметь в виду, что приложение не может фактически требовать, чтобы данные были согласованными все время. Например, в типичном веб-приложении электронной торговли, которое позволяет пользователю просматривать и приобретать товары, любые уровни запасов, представленные пользователю, скорее всего, будут статическими значениями, определяемыми при запросе сведений для элемента запаса. Если другой одновременный пользователь покупает один и тот же элемент, уровень запасов в системе будет уменьшаться, но это изменение, вероятно, не потребуется отражать в данных, отображаемых для первого пользователя. Если уровень запаса падает до нуля, и первый пользователь пытается приобрести элемент, система может либо предупредить пользователя о том, что товар сейчас отсутствует на складе, либо разместить элемент в обратном порядке, и сообщить пользователю, что время доставки может быть продлен.
Соображения для реализации окончательной согласованности
Конечная согласованность часто является предпочтительной моделью для управления распределенными данными в облачной среде, но есть много проблем, которые вы должны учитывать, если следовать этой модели. Эти проблемы лучше всего обобщаются с использованием примера. На рисунке 1 показано простое приложение электронной торговли, которое может извлечь выгоду из последовательного подхода к последовательности.
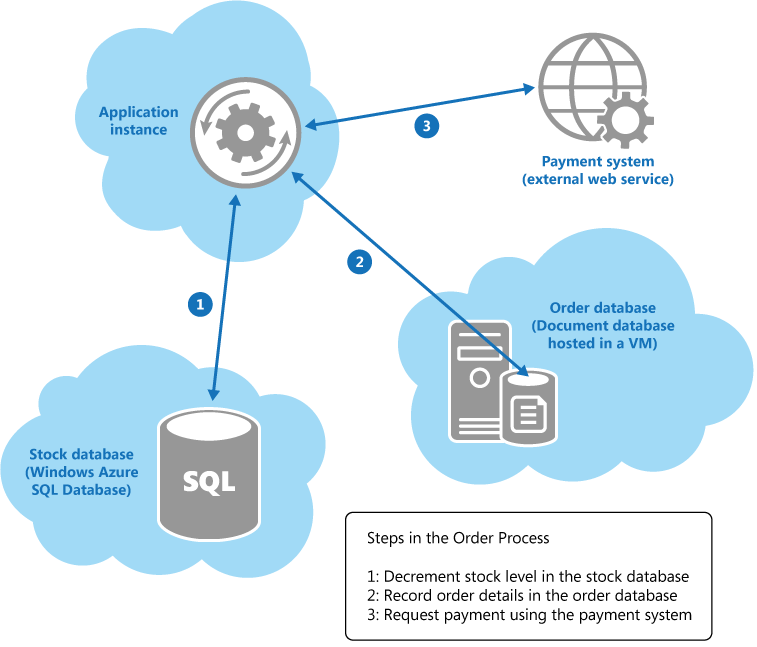
Когда клиент размещает заказ, экземпляр приложения выполняет следующие операции в коллекции разнородных хранилищ данных, хранящихся в разных местах:
- Обновите уровень запасов заказанного товара.
- Запишите детали заказа.
- Проверьте платежные реквизиты для заказа.
| Заметка: |
|---|
| В некоторых случаях хранилище данных может быть внешней службой, такой как платежная система, показанная на рисунке 1. |
Хотя эти операции представляют собой логическую транзакцию, попытка реализовать сильную последовательность транзакций в этом сценарии, вероятно, будет непрактичной. Вместо этого внедрение процесса заказа в качестве последовательной последовательности шагов, где каждый шаг процесса является, по сути, автономной операцией, является гораздо более масштабируемым решением. Хотя эти шаги продвигаются вперед, состояние общей системы является непоследовательным. Например, после того, как уровень запасов обновлен, но до того, как детали заказа были записаны, система временно потеряла некоторый запас. Однако, когда все этапы завершены, система возвращается к согласованному состоянию, и все элементы запаса могут учитываться.
Несмотря на то, что реализация конечной последовательности в этом примере представляется концептуально простой, разработчик должен убедиться, что система в конечном итоге становится последовательной. Другими словами, приложение отвечает за то, чтобы гарантировать, что все три этапа в процессе заказа завершены, или определение действий, которые необходимо предпринять, если какой-либо из шагов завершится с ошибкой. Как вы разрешаете эту ситуацию в любой заданной системе, это неизбежно зависит от конкретного приложения.
В качестве примера, показывающего, как вы можете реализовать согласованную систему, охватывающую различные хранилища данных, см. Главу 8 « Построение решения Polyglot » в руководстве «Доступ к данным для высокомасштабируемых решений: использование SQL, NoSQL и Polyglot Persistence» на MSDN. В следующих разделах этого руководства также содержатся некоторые предложения.
Повторная попытка неудачных шагов
В распределенной среде неспособность выполнить операцию часто связана с некоторой временной ошибкой (отказ связи всегда возможен). Если такой сбой происходит, приложение может предположить, что ситуация временная и просто попытаться повторить шаг, который не удался. Меньше переходных исключений, таких как сбой базы данных или виртуальной машины, также могут возникать, и средство может быть похоже: подождите, пока система будет восстановлена, а затем повторите попытку. Такой подход может привести к тому, что один и тот же шаг будет выполняться дважды, что может привести к нескольким обновлениям. Очень сложно разработать решение для предотвращения повторения этого повторения, но приложение должно попытаться сделать такое повторение безвредным.
Одна из стратегий заключается в том, чтобы каждый шаг операции был идемпотентным. Это означает, что шаг, который ранее был успешным, может быть повторен без фактического изменения состояния системы. Шаги, которые включают бизнес-операцию, естественно, сильно зависят от бизнес-логики вашей системы, и способ, которым вы их реализуете, будет в значительной степени зависеть от структуры данных. Определение идемпотентных шагов требует глубокого, специфичного для домена понимания вашей системы.
Некоторые шаги могут быть, естественно, идемпотентными. Например, шаг, который устанавливает конкретный элемент в определенное значение (например, «ZipCode = 11111»), может повторяться много раз, и результат всегда будет таким же. Однако естественная идемпотентность не всегда возможна. В системе, которая включает в себя сервисы, такие как платежная система, показанная в примере электронной торговли, может быть реализована некоторая форма искусственной идемпотентности. Общей методикой является связать сообщение, отправленное службе с уникальным идентификатором. Служба может хранить идентификатор для каждого сообщения, которое оно получает локально, и обрабатывать сообщение только в том случае, если идентификатор не совпадает с сообщением, полученным ранее. Этот метод известен как снятия с оболванивания (удаление дубликатов сообщений). Эта стратегия, примером которой являетсяИдемпотентный шаблон приемника , зависит от того, что служба может успешно сохранять идентификаторы сообщений.
| Заметка: |
|---|
| Дополнительные сведения об идемпотентности см. В разделе « Образцы правдоподобия» в блоге Джонатана Оливера. |
Разделение данных и использование идемпотентных команд
Несколько экземпляров приложения, конкурирующих для одновременного изменения одних и тех же данных, являются еще одной распространенной причиной отказа от возможной последовательности. Если возможно, вы должны разработать свою систему, чтобы свести к минимуму эти ситуации. Вы должны попытаться разбить вашу систему, чтобы убедиться, что одновременные экземпляры приложения, пытающегося выполнить одни и те же операции одновременно, не конфликтуют друг с другом.
Вместо того, чтобы думать о простых CRUD (создавать, извлекать, обновлять и удалять), вы можете структурировать свою систему вокруг атомных команд, которые выполняют бизнес-задачи в стиле идемпотент. Для получения дополнительной информации см. Шаблон «Разделение ответственности команд и запросов» . Команды в решении CQRS часто реализуются, следуя шаблону Sourcing . Event sourcing выполняет операции с данными, управляя задачами из последовательности событий, каждый из которых записывается в хранилище только для добавления.
| Заметка: |
|---|
| Для получения подробной информации об использовании CQRS и Event Sourcing для реализации возможной согласованности см. Ссылку 4: CQRS и ES Deep Dive на MSDN. |
Реализация компенсационной логики
В конечном итоге могут возникнуть ситуации, когда логика приложения определяет, что операция не может или не должна быть разрешена для завершения (это может быть связано с различными бизнес-соображениями). В этих случаях вы можете реализовать компенсационную логику, которая отменяет работу, выполняемую операцией, как описано в шаблоне компенсации .
В примере электронной торговли, показанном на рисунке 1, когда приложение выполняет каждый шаг процесса заказа, оно может записывать задачи, необходимые для отмены этого шага. Если процесс заказа выходит из строя, приложение может применять шаги «отменить» для каждого выполненного ранее шага, чтобы восстановить целостность системы. Этот метод может быть осложнен тем фактом, что отмена шага может быть не такой простой, как выполнение полной противоположности исходного шага, и могут существовать дополнительные бизнес-правила, которые должны применяться в приложении. Например, отменять шаг, который записывает детали заказа в базе данных документа, может быть не так просто, как удаление документа. Для целей аудита может потребоваться оставить исходный документ заказа на месте, но изменить статус заказа в этом документе на «отменен».
| Заметка: |
|---|
| Компенсация транзакций может быть сложной для реализации и дорогостоящей работы. Вы должны использовать их только там, где они абсолютно необходимы. |
Связанные шаблоны и руководства
Следующие шаблоны и рекомендации могут также иметь значение при управлении согласованностью в облачном приложении:
- Компенсация шаблона транзакций . Этот шаблон описывает, как отменить работу, выполняемую серией шагов, которые вместе определяют согласованную операцию, если одна или несколько операций завершаются с ошибкой.
- Шаблон разделения ответственности и запросов . В этом шаблоне описывается, как можно сегрегировать операции, которые считывают данные из операций, которые обновляют данные. Этот шаблон может использовать разные модели одних и тех же данных, и необходимо обеспечить, чтобы информация в этих моделях могла стать последовательной.
- Шаблон источника событий . Этот шаблон часто используется с шаблоном сегрегации ответа команд и запросов. Он может упростить задачи в сложных областях; повысить производительность, масштабируемость и оперативность; обеспечить согласованность данных транзакций; и поддерживать полные контрольные журналы и историю, которые могут позволить компенсирующие действия.
- Руководство по разделению данных . Во многих крупномасштабных приложениях данные делятся на отдельные разделы, которые можно управлять и получать по отдельности. Возможно, необходимо обеспечить соответствие данных между разделами.
- Репликация данных и руководство по синхронизации . Репликация и синхронизация данных могут помочь обеспечить максимальную доступность и производительность, обеспечить согласованность и минимизировать затраты на передачу данных между местоположениями.
- Кэширование . Данные в кэшах приложений могут становиться несогласованными между экземплярами и хранилищем данных, которое действует как исходный источник данных. В этом руководстве описывается, как кэши могут поддерживать политики истечения срока действия, которые могут помочь сократить период, в течение которого кэшированные данные несовместимы.
- Шаблон для кэша . В этом шаблоне описывается, как извлекать данные в кеш по требованию, поскольку данные необходимы приложению. Его можно использовать для хорошего эффекта, чтобы уменьшить накладные расходы, связанные с многократным доступом к тем же данным.
Больше информации
- Руководство по доступу к данным для высокомасштабируемых решений: использование SQL, NoSQL и Polyglot Persistence в MSDN.
- Идемпотентный приемник картина Грегора Хоупа и Бобби Вульф на сайте Enterprise Integration Patterns.
- Статья « Идемпотентные шаблоны» в блоге Джонатана Оливера.
- Ссылка 4: CQRS и ES Deep Dive на MSDN.
- Статья « В конечном счете согласуется» на веб-сайте ACM.
- Теорема CAP в Википедии.
Original(english): https://msdn.microsoft.com/library/dn589800.aspx
Translation: Basic, need improvment
Status: Draft
Action: Vote to improve