Data partitioning
Во многих крупномасштабных решениях данные делятся на отдельные разделы, которые можно управлять и получать отдельно. Стратегия разделения должна выбираться тщательно, чтобы максимизировать выгоды при минимизации неблагоприятных эффектов. Разделение может помочь улучшить масштабируемость, уменьшить конкуренцию и оптимизировать производительность. Еще одним преимуществом разделения является то, что он может обеспечить механизм деления данных по образцу использования. Например, вы можете архивировать более старые, менее активные (холодные) данные в более дешевом хранилище данных.1
Почему данные разделяются?
Большинство облачных приложений и сервисов хранят и извлекают данные как часть их операций. Конструкция хранилищ данных, которые использует приложение, может существенно влиять на производительность, пропускную способность и масштабируемость системы. Одним из методов, который обычно применяется в крупномасштабных системах, является разделение данных на отдельные разделы.
В этой статье термин « разделение» означает процесс физического разделения данных в отдельные хранилища данных. Это не то же самое, что разбиение таблиц SQL Server.
Разделение данных может предложить ряд преимуществ. Например, он может применяться для:
- Улучшите масштабируемость . Когда вы масштабируете единую систему баз данных, она в конечном итоге достигнет физического аппаратного ограничения. Если вы делите данные по нескольким разделам, каждый из которых размещен на отдельном сервере, вы можете масштабировать систему почти на неопределенный срок.
- Повысьте производительность . Операции доступа к данным на каждом разделе выполняются с меньшим объемом данных. При условии, что данные разделены соответствующим образом, разбиение может сделать вашу систему более эффективной. Операции, которые затрагивают более одного раздела, могут выполняться параллельно. Каждый раздел может быть расположен рядом с приложением, которое использует его для минимизации задержек сети.
- Улучшите доступность . Разделение данных на нескольких серверах позволяет избежать одной точки отказа. Если сервер выходит из строя или проходит плановое техническое обслуживание, недоступны только данные в этом разделе. Операции над другими разделами могут продолжаться. Увеличение количества разделов снижает относительное влияние отказа отдельного сервера, уменьшая процент данных, которые будут недоступны. Репликация каждого раздела может еще больше уменьшить вероятность сбоя одного раздела, влияющего на операции. Это также позволяет отделять критические данные, которые должны постоянно и высокодоступны из низкоценных данных, которые имеют более низкие требования к доступности (например, файлы журналов).
- Улучшение безопасности . В зависимости от характера данных и того, как они разбиты на разделы, можно было бы разделить чувствительные и нечувствительные данные на разные разделы и, следовательно, на разные серверы или хранилища данных. Затем безопасность может быть специально оптимизирована для чувствительных данных.
- Обеспечьте операционную гибкость . Разделение предоставляет множество возможностей для точной настройки, максимизации эффективности управления и минимизации затрат. Например, вы можете определить различные стратегии управления, мониторинга, резервного копирования и восстановления и другие административные задачи, основанные на важности данных в каждом разделе.
- Сопоставьте хранилище данных с образцом использования . Разделение позволяет разделить разделы на другой тип хранилища данных на основе стоимости и встроенных функций, которые предлагает хранилище данных. Например, большие двоичные данные могут храниться в хранилище данных blob, в то время как более структурированные данные могут храниться в базе данных документов. Дополнительные сведения см. В разделе Построение решения polyglot в руководстве по шаблонам и практикам и доступ к данным для высокомасштабируемых решений: использование стабильности SQL, NoSQL и полиглота на веб-сайте Microsoft.
Некоторые системы не реализуют разделение, потому что это считается скорее затратной, чем преимущественной. Основными причинами такого обоснования являются:
- Многие системы хранения данных не поддерживают объединения между разделами, и может быть трудно поддерживать ссылочную целостность в многораздельной системе. Часто бывает необходимо реализовать проверки целостности и целостности кода приложения (на уровне секционирования), что может привести к дополнительным сложностям ввода-вывода и приложений.
- Поддержание разделов не всегда является тривиальной задачей. В системе, где данные нестабильны, вам может потребоваться периодически перебалансировать разделы, чтобы уменьшить конфликты и «горячие точки».
- Некоторые общие инструменты не работают естественным образом с секционированными данными.
Проектирование разделов
Данные можно разделить по-разному: горизонтально, вертикально или функционально. Выбранная вами стратегия зависит от причины разделения данных и требований приложений и служб, которые будут использовать данные.
Заметка
Схемы секционирования, описанные в этом руководстве, объясняются таким образом, который не зависит от базовой технологии хранения данных. Они могут применяться ко многим типам хранилищ данных, включая реляционные и NoSQL-базы данных.
Стратегии разделения
Три типичные стратегии для разделения данных:
- Горизонтальное разбиение (часто называемое sharding ). В этой стратегии каждый раздел является хранилищем данных по своему усмотрению, но все разделы имеют одну и ту же схему. Каждый раздел известен как осколок и содержит определенное подмножество данных, такое как все заказы для определенного набора клиентов в приложении электронной коммерции.
- Вертикальное разбиение . В этой стратегии каждый раздел содержит подмножество полей для элементов в хранилище данных. Поля разделены в соответствии с их образцом использования. Например, часто используемые поля могут быть помещены в один вертикальный раздел и менее часто используемые поля в другом.
- Функциональное разбиение . В этой стратегии данные агрегируются в соответствии с тем, как они используются каждым ограниченным контекстом в системе. Например, система электронной коммерции, которая реализует отдельные бизнес-функции для выставления счетов и управления инвентаризацией продукта, может хранить данные счета в одном разделе и данные инвентаризации продукта в другом.
Важно отметить, что три описанные здесь стратегии могут быть объединены. Они не являются взаимоисключающими, и мы рекомендуем учитывать их все при разработке схемы разбиения. Например, вы можете разделить данные на осколки, а затем использовать вертикальное разбиение для дальнейшего разделения данных в каждом осколке. Аналогично, данные в функциональном разделе могут быть разделены на осколки (которые также могут быть разделены по вертикали).
Однако различные требования каждой стратегии могут вызвать ряд противоречивых вопросов. Вы должны оценить и сбалансировать все это при разработке схемы разделения, которая соответствует общим целям производительности обработки данных для вашей системы. В следующих разделах более подробно рассматриваются все стратегии.
Горизонтальное разбиение (окантовка)
На рисунке 1 показан обзор горизонтального разбиения или очертания. В этом примере данные инвентаризации продукта делятся на осколки на основе ключа продукта. Каждый осколок содержит данные для смежного диапазона ключей осколка (AG и HZ), организованных в алфавитном порядке.
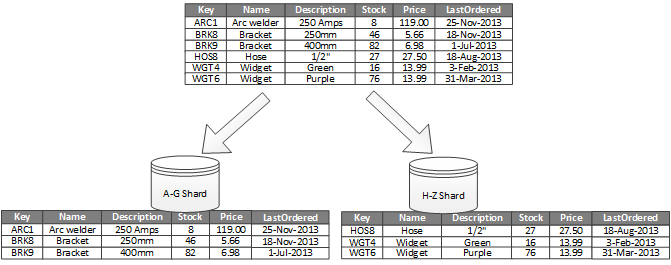
Рисунок 1. Горизонтальное разбиение (наложение) данных на основе ключа раздела
Sharding помогает распределить нагрузку на большее количество компьютеров, что уменьшает количество конкурентов и повышает производительность. Вы можете масштабировать систему, добавляя дополнительные осколки, которые запускаются на дополнительных серверах.
Важнейшим фактором при реализации этой стратегии разбиения является выбор ключа осколки. Слишком сложно изменить ключ после работы системы. Ключ должен обеспечивать разделение данных таким образом, чтобы рабочая нагрузка была как можно более возможной на всех участках.
Обратите внимание, что разные осколки не должны содержать одинаковые объемы данных. Скорее, тем более важным является баланс количества запросов. Некоторые осколки могут быть очень большими, но каждый элемент является объектом небольшого числа операций доступа. Другие осколки могут быть меньше, но каждый элемент доступен гораздо чаще. Также важно обеспечить, чтобы один осколок не превышал пределы шкалы (с точки зрения емкости и ресурсов обработки) хранилища данных, которые используются для размещения этого осколка.
Если вы используете схему осколков, избегайте создания горячих точек (или горячих разделов), которые могут повлиять на производительность и доступность. Например, если вы используете хэш идентификатора клиента вместо первой буквы имени клиента, вы предотвращаете несбалансированное распределение, которое является результатом обычных и менее обычных начальных букв. Это типичный метод, который помогает распределять данные более равномерно по разделам.
Выберите ключевой ключ, который минимизирует любые будущие требования, чтобы разделить большие осколки на более мелкие части, объединить небольшие осколки в большие разделы или изменить схему, которая описывает данные, хранящиеся в наборе разделов. Эти операции могут занять много времени и могут потребовать одновременного отключения одного или нескольких осколков в автономном режиме.
Если черепа реплицируются, возможно, что некоторые из реплик будут сохранены онлайн, а другие будут разделены, объединены или переконфигурированы. Тем не менее, системе может потребоваться ограничить операции, которые могут быть выполнены на данных в этих осколках, в то время как происходит реконфигурация. Например, данные в репликах могут быть помечены как «только для чтения», чтобы ограничить область несоответствий, которые могут возникнуть во время реорганизации осколков.
Для получения более подробной информации и рекомендаций по многим из этих соображений и методов эффективной практики проектирования хранилищ данных, которые реализуют горизонтальное разбиение, см. Шаблон .
Вертикальное разбиение
Наиболее часто используемым для вертикального разбиения является сокращение затрат ввода-вывода и производительности, связанных с получением наиболее часто используемых элементов. На рисунке 2 показан пример вертикального разбиения. В этом примере различные свойства для каждого элемента данных хранятся в разных разделах. В одном разделе хранятся данные, к которым обращаются чаще, включая имя, описание и информацию о ценах для продуктов. Другой содержит объем в запасе и последнюю дату заказа.
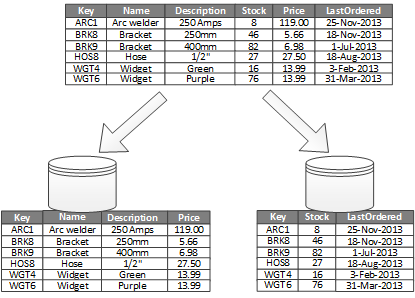
Рисунок 2. Вертикальное разделение данных по его образцу использования
В этом примере приложение регулярно запрашивает имя продукта, описание и цену при отображении деталей продукта клиентам. Уровень запаса и дата, когда товар был заказан последним у производителя, хранятся в отдельном разделе, потому что эти два элемента обычно используются вместе.
Эта схема разделения имеет дополнительное преимущество в том, что относительно медленные данные (название продукта, описание и цена) отделены от более динамических данных (уровень запасов и последняя упорядоченная дата). Приложению может быть полезно кэшировать медленные данные в памяти, если к ним часто обращаются.
Другим типичным сценарием для этой стратегии разбиения является максимизация безопасности конфиденциальных данных. Например, вы можете сделать это, сохранив номера кредитных карт и соответствующие номера проверки безопасности карты в отдельных разделах.
Вертикальное разбиение также может уменьшить объем параллельного доступа, который необходим для данных.
Вертикальное разбиение выполняется на уровне сущности в хранилище данных, частично нормализуя объект, чтобы разбить его на широкий элемент на набор узких элементов. Он идеально подходит для хранилищ данных, ориентированных на столбцы, таких как HBase и Cassandra. Если данные в коллекции столбцов вряд ли будут изменены, вы также можете рассмотреть возможность использования хранилищ столбцов в SQL Server.
Функциональное разбиение
Для систем, где можно идентифицировать ограниченный контекст для каждой отдельной бизнес-области или услуги в приложении, функциональное разбиение предоставляет технику для улучшения изоляции и доступа к данным. Другим распространенным использованием функционального разделения является разделение данных чтения и записи из данных только для чтения, которые используются для целей отчетности. На рисунке 3 показан обзор функционального разбиения, в котором данные инвентаризации отделены от данных клиента.
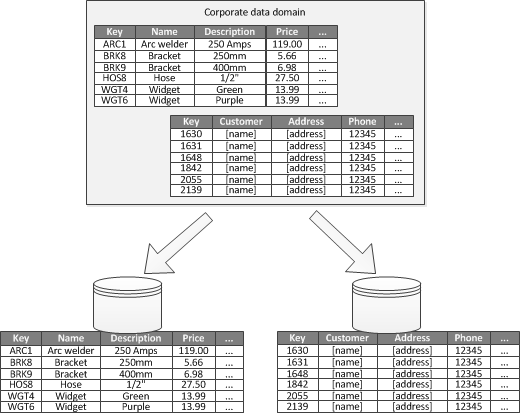
Рисунок 3. Функциональное разбиение данных на ограниченный контекст или субдомен
Эта стратегия разбиения может помочь уменьшить конфликт доступа к данным в разных частях системы.
Проектирование разделов для масштабируемости
Крайне важно учитывать размер и рабочую нагрузку для каждого раздела и балансировать их, чтобы распределять данные для достижения максимальной масштабируемости. Однако вы также должны разбивать данные таким образом, чтобы они не превышали пределы масштабирования для одного хранилища разделов.
Выполните следующие шаги при разработке разделов для масштабируемости:
- Проанализируйте приложение, чтобы понять шаблоны доступа к данным, такие как размер набора результатов, возвращаемого каждым запросом, частота доступа, неотъемлемая латентность и требования к обработке вычислений на стороне сервера. Во многих случаях несколько основных компаний будут требовать большую часть ресурсов обработки.
- Используйте этот анализ для определения текущих и будущих целей масштабируемости, таких как размер данных и рабочая нагрузка. Затем распределите данные по разделам для достижения цели масштабируемости. В стратегии горизонтального разбиения важно выбрать соответствующий ключ осколка, чтобы обеспечить равномерность распределения. Для получения дополнительной информации см. Шаблон Sharding .
- Убедитесь, что ресурсы, доступные для каждого раздела, достаточны для обработки требований к масштабируемости с точки зрения размера и пропускной способности данных. Например, узел, на котором размещается раздел, может наложить жесткий лимит на объем пространства для хранения, вычислительной мощности или пропускной способности сети, которые он предоставляет. Если требования к хранению и обработке данных, вероятно, превысят эти пределы, может потребоваться уточнить вашу стратегию разделения или разделить данные дальше. Например, одним из способов масштабирования может быть разделение данных регистрации из основных функций приложения. Вы делаете это, используя отдельные хранилища данных, чтобы не допустить, чтобы требования к хранилищу данных превышали ограничение масштабирования узла. Если общее количество хранилищ данных превышает ограничение узла, может потребоваться использование отдельных узлов хранения.
- Следите за используемой системой, чтобы убедиться, что данные распределены так, как ожидалось, и что разделы могут обрабатывать нагрузку, наложенную на них. Возможно, что использование не соответствует потребностям, ожидаемым анализом. В этом случае возможно перебалансировать разделы. В противном случае может потребоваться перепроектировать некоторые части системы, чтобы получить необходимый баланс.
Обратите внимание, что некоторые облачные среды выделяют ресурсы с точки зрения границ инфраструктуры. Убедитесь, что лимиты выбранной границы обеспечивают достаточный объем для ожидаемого роста объема данных с точки зрения хранения данных, мощности обработки и пропускной способности.
Например, если вы используете хранилище таблиц Azure, для занятого осколка может потребоваться больше ресурсов, чем доступно одному разделу для обработки запросов. (Ограничение объема запросов, которые могут быть обработаны одним разделом за определенный период времени, ограничено. Более подробную информацию см. На странице « Масштабируемость и целевые показатели масштабирования хранилища на веб-узле Microsoft».)
Если это так, осколок, возможно, потребуется перераспределить для распространения нагрузки. Если общий размер или пропускная способность этих таблиц превышает емкость учетной записи хранилища, может потребоваться создание дополнительных учетных записей хранилища и распространение таблиц в этих учетных записях. Если количество учетных записей хранения превышает количество учетных записей, доступных для подписки, может потребоваться несколько подписчиков.
Проектирование разделов для выполнения запросов
Производительность запроса часто может быть увеличена за счет использования меньших наборов данных и путем параллельных запросов. Каждый раздел должен содержать небольшую часть всего набора данных. Это уменьшение объема может повысить производительность запросов. Однако разделение не является альтернативой для надлежащего проектирования и настройки базы данных. Например, убедитесь, что у вас есть необходимые индексы, если вы используете реляционную базу данных.
Выполните следующие шаги при проектировании разделов для выполнения запросов:
- Изучите требования и производительность приложений:
- Используйте бизнес-требования для определения критических запросов, которые всегда должны выполняться быстро.
- Контролируйте систему, чтобы идентифицировать любые запросы, которые выполняются медленно.
- Установите, какие запросы выполняются наиболее часто. Один экземпляр каждого запроса может иметь минимальные затраты, но совокупное потребление ресурсов может быть значительным. Возможно, было бы полезно разделить данные, полученные этими запросами, на отдельный раздел или даже на кеш.
- Разделите данные, которые вызывают медленную работу:
- Ограничьте размер каждого раздела, чтобы время ответа на запрос находилось в пределах цели.
- Создайте ключ осколка, чтобы приложение могло легко найти раздел, если вы выполняете горизонтальное разбиение. Это предотвращает запрос от сканирования через каждый раздел.
- Рассмотрим расположение раздела. Если возможно, попытайтесь сохранить данные в разделах, которые географически близки к приложениям и пользователям, которые к нему обращаются.
- Если у объекта есть требования к производительности и производительности запросов, используйте функциональное разбиение на основе этого объекта. Если это все еще не удовлетворяет требованиям, примените также горизонтальное разбиение. В большинстве случаев достаточно одной стратегии разделения, но в некоторых случаях более эффективно сочетать обе стратегии.
- Рассмотрите возможность использования асинхронных запросов, которые выполняются параллельно по разделам для повышения производительности.
Проектирование разделов для доступности
Данные разделов могут улучшить доступность приложений, гарантируя, что весь набор данных не будет представлять собой единую точку отказа и что отдельные подмножества набора данных могут управляться независимо. Репликация разделов, содержащих критические данные, также может улучшить доступность.
При разработке и внедрении разделов учитывайте следующие факторы, которые влияют на доступность:
- Насколько важны данные для бизнес-операций . Некоторые данные могут включать критическую бизнес-информацию, такую как данные счета или банковские транзакции. Другие данные могут включать менее критические рабочие данные, такие как файлы журналов, трассировки производительности и т. Д. После определения каждого типа данных рассмотрите:
- Хранение критически важных данных в высокодоступных разделах с соответствующим планом резервного копирования.
- Создание отдельных механизмов и процедур управления и контроля для различных критических значений каждого набора данных. Поместите данные с одинаковым уровнем критичности в один и тот же раздел, чтобы их можно было скопировать вместе с соответствующей частотой. Например, разделы, содержащие данные для банковских транзакций, возможно, придется копировать чаще, чем разделы, содержащие данные ведения журнала или трассировки.
- Как управлять отдельными разделами . Проектирование разделов для поддержки независимого управления и обслуживания дает несколько преимуществ. Например:
- Если сбой раздела, его можно восстановить независимо, не затрагивая экземпляры приложений, которые обращаются к данным в других разделах.
- Разделение данных по географическим районам позволяет выполнять запланированные задачи обслуживания в непиковые часы для каждого местоположения. Убедитесь, что разделы не слишком велики, чтобы предотвратить запланированное техническое обслуживание в течение этого периода.
- Репликация критических данных по разделам . Эта стратегия может улучшить доступность и производительность, хотя она также может привести к проблемам согласованности. Требуется время для внесения изменений в данные в разделе, который будет синхронизирован с каждой репликой. В течение этого периода разные разделы будут содержать разные значения данных.
Понимание того, как разделение влияет на дизайн и разработку
Использование секционирования добавляет сложности к разработке и разработке вашей системы. Рассмотрите разбиение как фундаментальную часть проектирования системы, даже если система изначально содержит только один раздел. Если вы рассматриваете разделение как запоздалую мысль, когда система начинает испытывать проблемы с производительностью и масштабируемостью, сложность возрастает, потому что у вас уже есть действующая система для поддержки.
Если вы обновляете систему, чтобы включить разделение в этой среде, это требует изменения логики доступа к данным. Он также может включать перенос большого количества существующих данных для распределения его по разделам, часто, пока пользователи ожидают, что смогут продолжать использовать эту систему.
В некоторых случаях разделение не считается важным, поскольку исходный набор данных является небольшим и может быть легко обработан одним сервером. Это может быть справедливо в системе, которая, как ожидается, не будет превышать ее первоначальный размер, но многие коммерческие системы должны расширяться по мере увеличения числа пользователей. Это расширение обычно сопровождается ростом объема данных.
Также важно понимать, что разделение не всегда является функцией больших хранилищ данных. Например, небольшое хранилище данных может иметь большой доступ к сотням одновременных клиентов. Разделение данных в этой ситуации может помочь уменьшить конкуренцию и повысить пропускную способность.
При проектировании схемы разбиения данных рассмотрите следующие моменты:
- По возможности держите данные для наиболее общих операций с базой данных вместе в каждом разделе, чтобы минимизировать операции доступа к разным разделам . Запрос по разделам может быть более трудоемким, чем запрос только в пределах одного раздела, но оптимизация разделов для одного набора запросов может негативно повлиять на другие запросы. Когда вы не можете избежать запросов по разделам, минимизируйте время запроса, выполнив параллельные запросы и агрегируя результаты в приложении. Такой подход может быть невозможен в некоторых случаях, например, когда необходимо получить результат из одного запроса и использовать его в следующем запросе.
- Если в запросах используются относительно статические справочные данные, такие как таблицы почтовых индексов или списки продуктов, рассмотрите возможность репликации этих данных во всех разделах, чтобы уменьшить потребность в отдельных операциях поиска в разных разделах . Такой подход может также уменьшить вероятность того, что эталонные данные станут «горячим» набором данных, который подвержен интенсивному трафику со всей системы. Однако есть дополнительные затраты, связанные с синхронизацией любых изменений, которые могут возникнуть с этими справочными данными.
- По возможности минимизируйте требования к ссылочной целостности по вертикальным и функциональным разделам . В этих схемах само приложение отвечает за поддержание ссылочной целостности во всех разделах при обновлении и использовании данных. Запросы, которые должны объединять данные по нескольким разделам, выполняются медленнее, чем запросы, которые объединяют данные только в один и тот же раздел, потому что приложению обычно требуется выполнение последовательных запросов на основе ключа, а затем внешнего ключа. Вместо этого рассмотрите возможность репликации или де-нормализации соответствующих данных. Чтобы свести к минимуму время запроса, когда необходимы объединения между разделами, выполните параллельные запросы по разделам и соедините данные в приложении.
- Рассмотрим эффект, который может иметь схема разбиения на согласованность данных между разделами. Оцените, является ли сильная согласованность фактическим требованием. Вместо этого общий подход в облаке заключается в реализации возможной последовательности. Данные в каждом разделе обновляются отдельно, а логика приложения гарантирует, что все обновления успешно завершены. Он также обрабатывает несоответствия, которые могут возникнуть в результате запроса данных, в то время как в конечном итоге выполняется согласованная операция. Для получения дополнительной информации о реализации конечной согласованности см. Праймер согласования данных .
- Посмотрите, как запросы определяют правильный раздел . Если запрос должен проверять все разделы, чтобы найти нужные данные, существенное влияние на производительность оказывает, даже если выполняется несколько параллельных запросов. Запросы, которые используются с вертикальными и функциональными стратегиями разбиения, могут, естественно, определять разделы. Однако горизонтальное разбиение (окантовка) может затруднить определение местоположения предмета, поскольку каждый осколок имеет одну и ту же схему. Типичным решением для ошпаривания является сохранение карты, которая может использоваться для поиска местоположения осколков для определенных элементов данных. Эта карта может быть реализована в логике осколков приложения или храниться в хранилище данных, если она поддерживает прозрачное очертание.
- При использовании стратегии горизонтального разбиения учитывайте периодическое перебалансирование осколков . Это позволяет равномерно распределять данные по размеру и рабочей нагрузке, чтобы минимизировать горячие точки, максимизировать производительность запросов и ограничивать физические ограничения. Однако это сложная задача, которая часто требует использования настраиваемого инструмента или процесса.
- Если вы копируете каждый раздел, он обеспечивает дополнительную защиту от сбоя . Если сбой одной копии невозможен, запросы могут быть направлены на рабочую копию.
- Если вы достигнете физических пределов стратегии разбиения, вам может потребоваться расширить масштабируемость на другой уровень . Например, если разделение находится на уровне базы данных, вам может потребоваться найти или реплицировать разделы в нескольких базах данных. Если разделение уже находится на уровне базы данных, а физические ограничения — проблема, это может означать, что вам нужно найти или реплицировать разделы в нескольких учетных записях хостинга.
- Избегайте транзакций, которые обеспечивают доступ к данным в нескольких разделах . Некоторые хранилища данных реализуют последовательность транзакций и целостность для операций, которые изменяют данные, но только тогда, когда данные находятся в одном разделе. Если вам нужна поддержка транзакций по нескольким разделам, вам, вероятно, потребуется реализовать это как часть вашей логики приложения, потому что большинство систем разбиения не предоставляют встроенную поддержку.
Для всех хранилищ данных требуется оперативное управление и мониторинг. Задачи могут варьироваться от загрузки данных, резервного копирования и восстановления данных, реорганизации данных и обеспечения правильной и эффективной работы системы.
Рассмотрим следующие факторы, влияющие на оперативное управление:
- Как реализовать соответствующие управленческие и операционные задачи при разделении данных . Эти задачи могут включать резервное копирование и восстановление, архивирование данных, мониторинг системы и другие административные задачи. Например, сохранение логической последовательности при выполнении операций резервного копирования и восстановления может стать проблемой.
- Как загрузить данные на несколько разделов и добавить новые данные, поступающие из других источников . Некоторые инструменты и утилиты могут не поддерживать операции с отложенными данными, такие как загрузка данных в правильный раздел. Это означает, что вам, возможно, придется создавать или получать новые инструменты и утилиты.
- Как архивировать и удалять данные на регулярной основе . Чтобы предотвратить чрезмерный рост разделов, вам необходимо регулярно архивировать и удалять данные (возможно, ежемесячно). Возможно, необходимо преобразовать данные в соответствии с другой схемой архива.
- Как найти проблемы с целостностью данных . Рассмотрите возможность запуска периодического процесса для обнаружения любых проблем с целостностью данных, таких как данные в одном разделе, которые ссылаются на недостающую информацию в другой. Процесс может либо попытаться исправить эти проблемы автоматически, либо поднять предупреждение оператору, чтобы исправить проблемы вручную. Например, в приложении электронной коммерции информация о заказе может храниться в одном разделе, но позиции, которые составляют каждый заказ, могут храниться в другом. Процесс размещения заказа должен добавить данные в другие разделы. Если этот процесс выходит из строя, могут быть сохранены строки, для которых нет соответствующего порядка.
Различные технологии хранения данных обычно предоставляют свои собственные функции для поддержки разделения. В следующих разделах представлены параметры, которые реализуются хранилищами данных, обычно используемыми приложениями Azure. Они также описывают соображения для разработки приложений, которые могут наилучшим образом использовать эти возможности.
Стратегии разделения для базы данных Azure SQL
База данных Azure SQL — это реляционная база данных как услуга, которая работает в облаке. Он основан на Microsoft SQL Server. Реляционная база данных делит информацию на таблицы, и каждая таблица содержит информацию об объектах как ряд строк. Каждая строка содержит столбцы, в которых хранятся данные для отдельных полей объекта. Страница Что такое база данных Azure SQL? на веб-сайте Microsoft содержится подробная документация о создании и использовании баз данных SQL.
Горизонтальное разбиение с помощью эластичной базы данных
Единая база данных SQL имеет ограничение на объем данных, который может содержать. Пропускная способность ограничена архитектурными факторами и количеством поддерживаемых параллельных соединений. Функция Elastic Database базы данных SQL поддерживает горизонтальное масштабирование базы данных SQL. Используя Elastic Database, вы можете разбить свои данные на осколки, которые распространяются по нескольким базам данных SQL. Вы также можете добавлять или удалять осколки, поскольку объем данных, которые необходимо обрабатывать, растет и сжимается. Использование Elastic Database также может помочь уменьшить конкуренцию путем распределения нагрузки между базами данных.
Заметка
Эластичная база данных заменяет функцию федераций базы данных Azure SQL. Существующие установки базы данных SQL Database могут быть перенесены в Elastic Database с помощью утилиты миграции Federations. Кроме того, вы можете реализовать свой собственный механизм осколки, если ваш сценарий не поддается естественным образом функциям, предоставляемым Elastic Database.
Каждый осколок реализован как база данных SQL. Осколок может содержать более одного набора данных (называемого окорочком ). Каждая база данных поддерживает метаданные, которые описывают связанные с ними окорочки. Гардероб может быть единственным элементом данных, или он может представлять собой группу элементов, имеющих один и тот же ключ. Например, если вы опрашиваете данные в многозадачном приложении, ключ окошка может быть идентификатором арендатора, и все данные для данного арендатора могут быть сохранены как часть одного и того же окопа. Данные для других арендаторов будут проводиться в разных оврагах.
Ответственность программиста заключается в связывании набора данных с ключом маршрута. Отдельная база данных SQL выступает в качестве глобального менеджера карт осколков. Эта база данных содержит список всех осколков и окорок в системе. Клиентское приложение, которое обращается к данным, сначала подключается к глобальной базе данных диспетчера карт осколков, чтобы получить копию карты осколков (список осколков и окорок), которую она затем кэширует локально.
Затем приложение использует эту информацию для маршрутизации запросов данных к соответствующему осколку. Эта функциональность скрыта за рядом API-интерфейсов, которые содержатся в клиентской библиотеке Elastic Database Database Database Azure SQL, которая доступна в виде пакета NuGet. Обзор страницы « Упругие базы данных» на веб-сайте Microsoft содержит более подробное введение в Elastic Database.
Заметка
Вы можете реплицировать глобальную базу данных менеджера карт, чтобы уменьшить латентность и улучшить доступность. Если вы реализуете базу данных с помощью одного из уровней ценообразования Premium, вы можете настроить активную георепликацию для непрерывной копирования данных в базы данных в разных регионах. Создайте копию базы данных в каждом регионе, в котором находятся пользователи. Затем настройте приложение для подключения к этой копии, чтобы получить карту осколков.
Альтернативный подход заключается в использовании Azure SQL Data Sync или конвейера Azure Data Factory для репликации базы данных менеджера карт осколков по регионам. Эта форма репликации выполняется периодически и является более подходящей, если карта осколков меняется нечасто. Кроме того, базу данных менеджера карт осколков не нужно создавать с использованием уровня цен Premium.
Elastic Database предоставляет две схемы для сопоставления данных в окорока и хранения их в осколках:
- Карта список осколок описывает связь между одним ключом и shardlet. Например, в многопользовательской системе данные для каждого арендатора могут быть связаны с уникальным ключом и сохранены в его собственном гарду. Чтобы гарантировать конфиденциальность и изоляцию (т. Е. Чтобы один арендатор не исчерпал ресурсы хранения данных, доступные другим), каждый окорок может храниться в пределах собственного осколка.
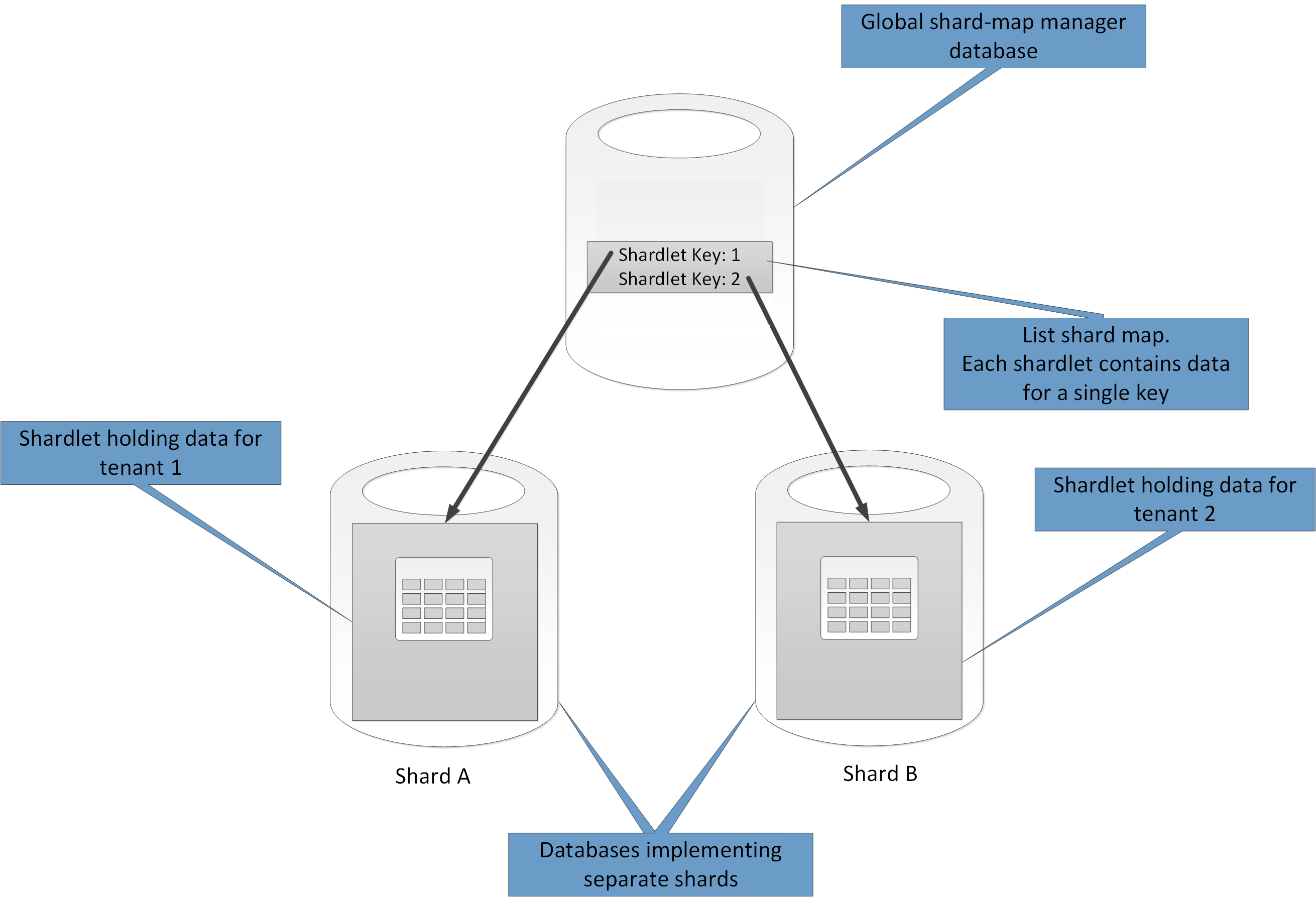
Рисунок 4. Использование карты списка карт для хранения данных арендатора в отдельных осколках
- Карта диапазона осколка описывает связь между множеством смежных ключевых значений и shardlet. В описанном ранее примере мультитентанта, в качестве альтернативы реализации выделенных окорок, вы можете группировать данные для набора арендаторов (каждый со своим собственным ключом) в пределах одного и того же окопа. Эта схема дешевле первой (поскольку арендаторы используют ресурсы хранения данных), но также создает риск снижения конфиденциальности и изоляции данных.
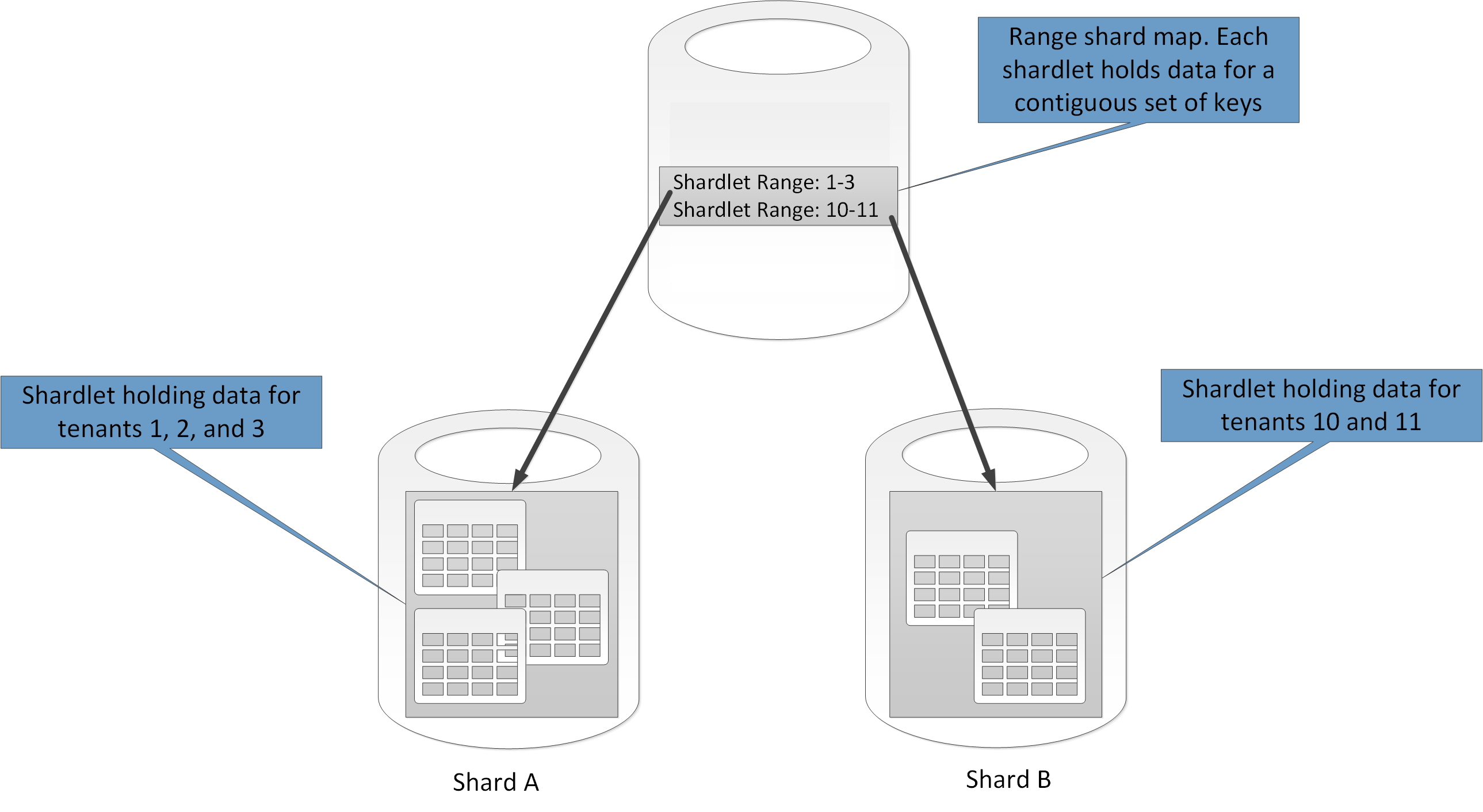
Рисунок 5. Использование карты осколков диапазона для хранения данных для ряда арендаторов в осколке+
Обратите внимание, что один осколок может содержать данные для нескольких окорок. Например, вы можете использовать перетаскивания списка для хранения данных для разных несмежных арендаторов в одном и том же осколке. Вы также можете смешивать диапазонные окорочки и список окорок в одном и том же осколке, хотя они будут адресованы через разные карты в глобальной базе данных карт карт. (Глобальная база данных карт карт может содержать несколько карт осколков.) На рисунке 6 показан этот подход.
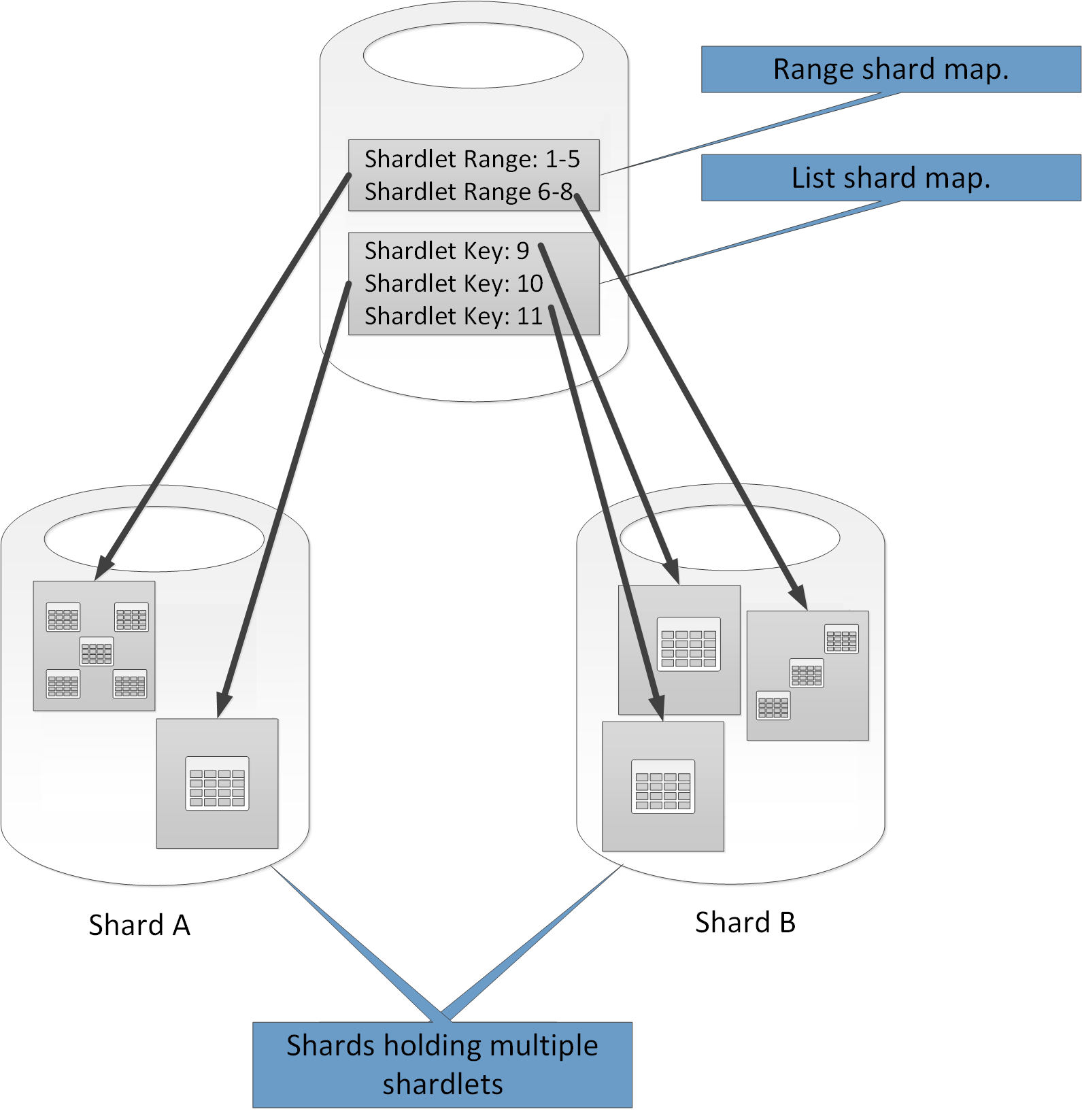
Рисунок 6. Внедрение множественных карт осколков
Используемая вами схема разбиения может существенно повлиять на производительность вашей системы. Он также может влиять на скорость, с которой необходимо добавить или удалить осколки, или скорость, с которой данные должны быть переразделены по осколкам. При использовании Elastic Database для разделения данных рассмотрите следующие моменты:
- Групповые данные, которые используются вместе в одном осколке, и избегают операций, требующих доступа к данным, хранящимся в нескольких осколках. Имейте в виду, что с помощью Elastic Database осколок представляет собой базу данных SQL в своем собственном праве, а база данных Azure SQL не поддерживает междоменные объединения (которые должны выполняться на стороне клиента). Помните также, что в Azure SQL Database ограничения ссылочной целостности, триггеры и хранимые процедуры в одной базе данных не могут ссылаться на объекты в другой. Поэтому не создавайте систему, которая имеет зависимости между осколками. Однако база данных SQL может содержать таблицы, содержащие копии справочных данных, часто используемых запросами и другими операциями. Эти таблицы не должны принадлежать какому-либо конкретному окороку. Репликация этих данных через осколки может помочь устранить необходимость объединения данных, охватывающих базы данных. Идеально,
Заметка
Хотя SQL Database не поддерживает объединение кросс-баз данных, вы можете выполнять кросс-осколочные запросы с помощью API-интерфейсов Elastic. Эти запросы могут прозрачно проходить через данные, хранящиеся во всех окопах, на которые ссылается карта осколков. API эластичной базы данных разбивает запросы кросс-осколков вниз на ряд отдельных запросов (по одному для каждой базы данных), а затем объединяет результаты. Для получения дополнительной информации см. Страницу Многостраничный запрос на веб-сайте Microsoft.
- Данные, хранящиеся в окопах, принадлежащих к одной карте осколков, должны иметь одну и ту же схему. Например, не создавайте карту осколков списка, которая указывает на некоторые окорочки, содержащие данные арендатора и другие окорочки, содержащие информацию о продукте. Это правило не применяется Elastic Database, но управление данными и запрос становятся очень сложными, если каждый окорок имеет другую схему. В приведенном выше примере хорошим решением является создание двух карт списка карт: один, который ссылается на данные арендатора, а другой — на информацию о продукте. Помните, что данные, относящиеся к разным окорочкам, могут храниться в одном осколке.
Заметка
Функциональность запросов кросс-осколков API-интерфейса Elastic зависит от каждого окошка на карте осколков, содержащей ту же схему.
- Транзакционные операции поддерживаются только для данных, которые хранятся внутри одного и того же осколка, а не по осколкам. Транзакции могут охватывать окорока, если они являются частью одного и того же осколка. Поэтому, если вашей бизнес-логике необходимо выполнять транзакции, либо хранить затронутые данные в том же осколке, либо реализовать возможную согласованность. Для получения дополнительной информации см. Праймер согласования данных .
- Поместите осколки близко к пользователям, которые обращаются к данным в этих осколках (другими словами, геолокация осколков). Эта стратегия помогает уменьшить задержку.
- Избегайте наличия смеси высокоактивных (горячих точек) и относительно неактивных осколков. Попробуйте равномерно распределить нагрузку по осколкам. Для этого может потребоваться хэширование клавиш.
- Если вы располагаете геолокационными осколками, убедитесь, что хешированные ключи сопоставляются с окороками, хранящимися в осколках, хранящимися рядом с пользователями, которые обращаются к этим данным.
- В настоящее время поддерживается только ограниченный набор типов данных SQL в виде ключей осле; int, bigint, varbinary и uniqueidentifier . Типы SQL int и bigint соответствуют типам данных int и long в C # и имеют одинаковые диапазоны. Тип varbinary SQL можно обрабатывать с помощью массива Byte в C #, а тип SQL uniqueidentier соответствует классу Guid в .NET Framework.
Как следует из названия, Elastic Database позволяет системе добавлять и удалять осколки, поскольку объем данных сжимается и растет. API-интерфейсы в клиентской библиотеке базы данных Azure SQL Database Elastic позволяют приложению создавать и удалять осколки динамически (и прозрачно обновлять диспетчер карт осколков). Однако удаление осколка — это деструктивная операция, которая также требует удаления всех данных в этом осколке.
Если приложение должно разделить осколок на два отдельных осколка или объединить осколки, Elastic Database предоставляет отдельную услугу сплит-слиянием. Эта служба выполняется в облачной службе (которая должна быть создана разработчиком) и безопасно переносит данные между осколками. Дополнительные сведения см. В разделе « Масштабирование» с помощью инструмента «Сплит-слияние» с помощью Elastic Database на веб-сайте Microsoft.
Стратегии разделения на Azure Storage
Лазерное хранилище обеспечивает четыре абстракции для управления данными:
- Хранилище Blob хранит данные неструктурированных объектов. Блоком может быть любой тип текстовых или двоичных данных, таких как документ, мультимедийный файл или программа установки. Хранилище памяти также упоминается как хранилище объектов.
- Хранилище таблиц хранит структурированные наборы данных. Хранилище таблиц — это хранилище данных атрибутов ключей NoSQL, которое позволяет быстро развиваться и быстро обращаться к большим количествам данных.
- Queue Storage обеспечивает надежную передачу сообщений для обработки рабочего процесса и для связи между компонентами облачных сервисов.
- Файловое хранилище предлагает совместное хранилище для устаревших приложений с использованием стандартного протокола SMB. Виртуальные машины Azure и облачные сервисы могут обмениваться файловыми данными между компонентами приложения через смонтированные домены, а локальные приложения могут получать доступ к файлам данных в общем доступе через API REST файлов.
Хранилище таблиц и хранилище памяти являются хранилищами ключевого значения, которые оптимизированы для хранения структурированных и неструктурированных данных соответственно. Очереди хранения обеспечивают механизм для создания слабосвязанных масштабируемых приложений. Хранилище таблиц, хранилище файлов, хранилище памяти и очереди хранения создаются в контексте учетной записи хранилища Azure. Учетные записи хранилища поддерживают три вида избыточности:
- Локально избыточное хранилище , которое поддерживает три копии данных в одном центре данных. Эта форма избыточности защищает от отказа оборудования, но не от бедствия, которое охватывает весь центр обработки данных.
- Зонально-избыточное хранилище , которое поддерживает три копии данных, распространяемых в разных датацентрах в одном регионе (или в двух географически близких регионах). Эта форма резервирования может защищать от бедствий, которые происходят в одном центре данных, но не может защитить от крупномасштабных сетевых отключений, которые влияют на весь регион. Обратите внимание, что зональное резервирование в настоящее время доступно только для блочных блоков.
- Гео-избыточное хранилище , которое хранит шесть копий данных: три копии в одном регионе (ваш локальный регион) и еще три копии в удаленном регионе. Такая форма резервирования обеспечивает наивысший уровень защиты от стихийных бедствий.
Microsoft опубликовала цели масштабируемости для Azure Storage. Дополнительные сведения см. На странице « Возможности масштабирования и производительности Azure Storage» на веб-сайте Microsoft. В настоящее время общая емкость хранилища не может превышать 500 ТБ. (Это включает в себя размер данных, хранящихся в хранилище таблиц, хранение файлов и хранилище blob, а также выдающиеся сообщения, хранящиеся в очереди хранения).
Максимальная скорость запроса для учетной записи хранилища (при условии, что размер 1 KB, размер блока или размер сообщения) составляет 20 000 запросов в секунду. У учетной записи хранилища не более 1000 IOPS (размер 8 КБ) на общий ресурс файла. Если ваша система, вероятно, превзойдет эти ограничения, подумайте о разделении нагрузки на несколько учетных записей. Одна подписка Azure может создавать до 200 учетных записей. Однако обратите внимание, что эти ограничения со временем могут меняться.
Разделение хранилища таблиц Azure
Хранилище таблиц Azure — это хранилище ключей, которое предназначено для разбиения на разделы. Все объекты хранятся в разделе, а разделы управляются внутри хранилища таблицы Azure. Каждый объект, который хранится в таблице, должен предоставить ключ из двух частей, который включает в себя:
- Ключ раздела . Это строковое значение, которое определяет, в каком хранилище таблицы Azure будет помещен объект. Все объекты с одним и тем же ключом раздела будут сохранены в одном разделе.
- Строковый ключ . Это другое строковое значение, которое идентифицирует объект внутри раздела. Все объекты внутри раздела сортируются лексически, в порядке возрастания, с помощью этого ключа. Комбинация клавиш ключа / строки ключа должна быть уникальной для каждого объекта и не может превышать 1 КБ.
Остальная часть данных для объекта состоит из полей, определенных приложением. Никакие конкретные схемы не применяются, и каждая строка может содержать другой набор полей, определенных приложением. Единственное ограничение заключается в том, что максимальный размер объекта (включая разделы и строки) в настоящее время составляет 1 МБ. Максимальный размер таблицы составляет 200 ТБ, хотя эти цифры могут измениться в будущем. (Проверьте информацию о масштабируемости и производительности Azure Storage на веб-сайте Microsoft для получения последней информации об этих ограничениях.)
Если вы пытаетесь сохранить объекты, превышающие эту емкость, рассмотрите их разделение на несколько таблиц. Используйте вертикальное разбиение, чтобы разделить поля на группы, которые, скорее всего, будут доступны вместе.
На рисунке 7 показана логическая структура примерной учетной записи хранилища (Contoso Data) для фиктивного приложения электронной коммерции. Учетная запись хранилища содержит три таблицы: информация о клиенте, информация о продукте и информация о заказе. Каждая таблица имеет несколько разделов.
В таблице «Информация о клиенте» данные разбиваются на разделы в соответствии с городом, в котором находится клиент, а ключ строки содержит идентификатор клиента. В таблице «Информация о продукте» продукты разделяются по категориям продуктов, а строка содержит номер продукта. В таблице «Информация о заказе» заказы разбиваются на дату, на которую они были помещены, а ключ строки указывает время получения заказа. Обратите внимание, что все данные упорядочиваются ключом строки в каждом разделе.
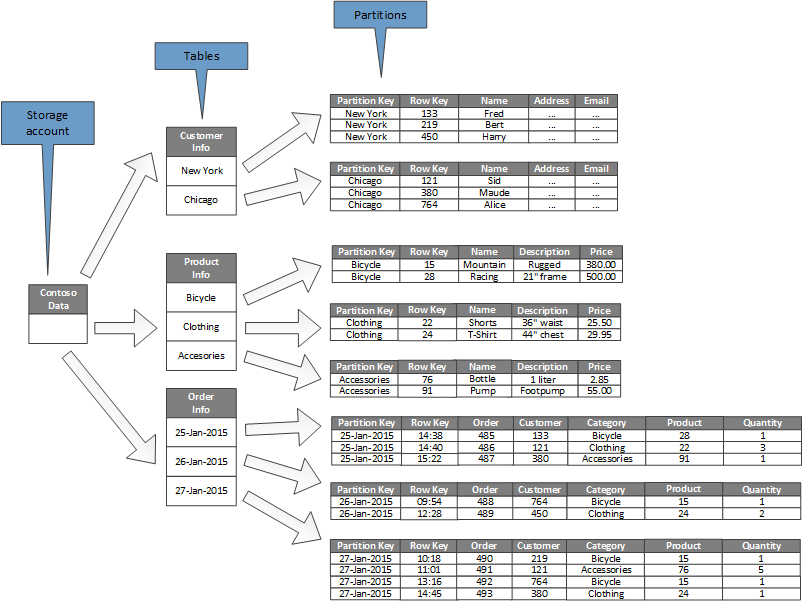
Рисунок 7. Таблицы и разделы в примере учетной записи хранилища
Заметка
В хранилище таблиц Azure также добавляется поле метки времени для каждого объекта. Поле timestamp поддерживается хранилищем таблиц и обновляется каждый раз, когда объект модифицируется и записывается обратно в раздел. Служба хранения таблиц использует это поле для реализации оптимистического параллелизма. (Каждый раз, когда приложение записывает объект обратно в хранилище таблиц, служба хранения таблиц сравнивает значение метки времени в сущности, которая записывается со значением, которое хранится в хранилище таблиц. Если значения различны, это означает, что другое приложение должно изменили объект с момента последнего получения, и операция записи завершилась неудачно. Не изменяйте это поле в своем собственном коде и не указывайте значение для этого поля при создании нового объекта.
В хранилище таблиц Azure используется ключ раздела, чтобы определить, как хранить данные. Если объект добавлен в таблицу с ранее неиспользуемым ключом раздела, хранилище таблицы Azure создает новый раздел для этого объекта. Другие объекты с одним и тем же ключом раздела будут сохранены в одном разделе.
Этот механизм эффективно реализует стратегию автоматического масштабирования. Каждый раздел хранится на одном сервере в центре данных Azure, чтобы гарантировать, что запросы, которые извлекают данные из одного раздела, выполняются быстро. Однако разные разделы могут быть распределены между несколькими серверами. Кроме того, один сервер может содержать несколько разделов, если эти разделы ограничены по размеру.
При проектировании ваших объектов для хранения таблиц Azure рассмотрите следующие моменты:
- Выбор ключей раздела и значений ключа строки должен определяться путем доступа к данным. Выберите комбинацию клавиш разделов / строк, которая поддерживает большинство ваших запросов. Наиболее эффективные запросы извлекают данные, указывая ключ раздела и ключ строки. Запросы, которые определяют ключ раздела и ряд ключей строк, могут быть завершены путем сканирования одного раздела. Это относительно быстро, потому что данные хранятся в строчном порядке строк. Если в запросах не указывается, какой раздел сканировать, ключ раздела может потребовать, чтобы хранилище таблиц Azure сканировало каждый раздел для ваших данных.
Наконечник
Если у объекта есть один естественный ключ, используйте его как ключ раздела и укажите пустую строку в качестве ключа строки. Если у объекта есть составной ключ, содержащий два свойства, выберите самое медленное изменяющееся свойство в качестве ключа раздела, а другое — как строку. Если объект имеет более двух ключевых свойств, используйте конкатенацию свойств для предоставления ключей разделов и строк.
- Если вы регулярно выполняете запросы, которые ищут данные, используя поля, отличные от ключей разделов и строк, рассмотрите возможность применения шаблона таблицы индексов .
- Если вы создаете ключи разделов, используя монотонную возрастающую или уменьшающуюся последовательность (например, «0001», «0002», «0003» и т. Д.), И каждый раздел содержит только ограниченный объем данных, тогда хранилище таблиц Azure может физически группироваться эти разделы вместе на одном сервере. Этот механизм предполагает, что приложение, скорее всего, будет выполнять запросы в смежном диапазоне разделов (запросы диапазона) и оптимизировано для этого случая. Однако этот подход может привести к тому, что горячие точки сосредоточены на одном сервере, потому что все вставки новых объектов, вероятно, будут сосредоточены на одном конце или другом смежных диапазонах. Это также может уменьшить масштабируемость. Чтобы распределить нагрузку более равномерно по серверам, рассмотрите хэширование ключа раздела, чтобы сделать последовательность более случайной.
- Настольное хранилище Azure поддерживает транзакционные операции для объектов, принадлежащих к одному разделу. Это означает, что приложение может выполнять несколько операций вставки, обновления, удаления, замены или слияния в виде атомного блока (при условии, что транзакция не включает более 100 объектов, а полезная нагрузка запроса не превышает 4 МБ) , Операции, которые охватывают несколько разделов, не являются транзакционными, и могут потребовать, чтобы вы реализовали возможную согласованность, как описано праймером согласования данных . Для получения дополнительной информации о хранении и транзакциях таблиц перейдите на страницу Выполнение транзакций группы лиц на веб-сайте Microsoft.
- Уделите особое внимание детализации ключа раздела из-за следующих причин:
- Использование одного и того же ключа раздела для каждого объекта приводит к тому, что служба хранения таблиц создает один большой раздел, который хранится на одном сервере. Это предотвращает его масштабирование и вместо этого фокусирует нагрузку на одном сервере. В результате этот подход подходит только для систем, которые управляют небольшим количеством объектов. Однако этот подход гарантирует, что все сущности могут участвовать в транзакциях группы организаций.
- Использование уникального ключа раздела для каждого объекта приводит к тому, что служба хранения таблиц создает отдельный раздел для каждого объекта, что может привести к большому количеству небольших разделов (в зависимости от размера сущностей). Этот подход более масштабируемый, чем использование одного ключа раздела, но транзакции группы лиц невозможны. Кроме того, запросы, которые извлекают более одного объекта, могут включать чтение из нескольких серверов. Однако, если приложение выполняет запросы диапазона, то использование монотонной последовательности для генерации ключей разделов может помочь оптимизировать эти запросы.
- Совместное использование ключа раздела в подмножестве объектов позволяет группировать связанные объекты в одном разделе. Операции, которые связаны с связанными объектами, могут выполняться с использованием транзакций группы сущностей, а запросы, которые извлекают набор связанных объектов, могут быть удовлетворены путем обращения к одному серверу.
Дополнительные сведения о разделении данных в хранилище таблиц Azure см. В статье « Руководство по дизайну таблицы хранилища Azure» на веб-сайте Microsoft.
Разбиение хранилища Azure
Хранилище Azure blob позволяет хранить большие двоичные объекты — в настоящее время размер до 5 ТБ для блочных блоков или 1 ТБ для страниц. (Для получения последней информации перейдите на страницу « Масштабируемость и целевые показатели Azure Storage на веб-сайте Microsoft».) Используйте блочные капли в таких сценариях, как потоковая передача, когда вам нужно быстро загружать или загружать большие объемы данных. Используйте капли страницы для приложений, для которых требуется случайный, а не последовательный доступ к частям данных.
Каждый блок (блок или страница) удерживается в контейнере в учетной записи хранилища Azure. Вы можете использовать контейнеры для группировки связанных блоков, которые имеют одинаковые требования безопасности. Эта группировка логична, а не физическая. Внутри контейнера каждый blob имеет уникальное имя.
Ключ раздела для blob — имя учетной записи + имя контейнера + имя blob. Это означает, что каждый blob может иметь свой собственный раздел, если это требует загрузка на blob. Блоки могут быть распределены на многих серверах, чтобы ограничить доступ к ним, но один blob может обслуживаться только одним сервером.
Действия записи одного блока (блочного блоба) или страницы (блочный блок) являются атомарными, но операции, которые охватывают блоки, страницы или капли, не являются. Если вам необходимо обеспечить согласованность при выполнении операций записи между блоками, страницами и блоками, выньте блокировку записи, используя аренду blob.
В хранилище Azure blob предусмотрена скорость передачи до 60 МБ в секунду или 500 запросов в секунду для каждого блоба. Если вы ожидаете, что превзойдете эти ограничения, а данные blob будут относительно статичными, рассмотрите репликацию капель с помощью сети доставки контента Azure. Для получения дополнительной информации см. Страницу « Сеть доставки контента Azure» на веб-сайте Microsoft. Дополнительные рекомендации и рекомендации см. В разделе Использование сети доставки контента Azure .
Разделение очередей хранения Azure
Лазерные очереди хранения позволяют реализовать асинхронную передачу сообщений между процессами. Учетная запись Azure может содержать любое количество очередей, и каждая очередь может содержать любое количество сообщений. Единственное ограничение — это пространство, доступное в учетной записи хранилища. Максимальный размер отдельного сообщения составляет 64 КБ. Если вам нужны сообщения, большие, чем это, тогда вместо этого используйте очереди Azure Service Bus.
Каждая очередь хранения имеет уникальное имя в учетной записи хранилища, которая ее содержит. Azure разбивает очереди на основе имени. Все сообщения для одной очереди хранятся в одном разделе, который управляется одним сервером. Различные очереди могут управляться разными серверами, чтобы помочь сбалансировать нагрузку. Распределение очередей на серверы прозрачно для приложений и пользователей.
В крупномасштабном приложении не используйте одну и ту же очередь хранения для всех экземпляров приложения, поскольку этот подход может привести к тому, что сервер, на котором размещена очередь, станет точкой доступа. Вместо этого используйте разные очереди для разных функциональных областей приложения. Лазерные очереди хранения не поддерживают транзакции, поэтому направление сообщений в разные очереди должно незначительно влиять на последовательность сообщений.
Очередь хранения Azure может обрабатывать до 2000 сообщений в секунду. Если вам нужно обрабатывать сообщения с большей скоростью, чем это, подумайте о создании нескольких очередей. Например, в глобальном приложении создайте отдельные очереди хранения в отдельных учетных записях хранилища для обработки экземпляров приложений, работающих в каждом регионе.
Стратегии разделения для Azure Service Bus
Azure Service Bus использует брокер сообщений для обработки сообщений, отправленных в очередь или тему служебной шины. По умолчанию все сообщения, отправленные в очередь или тему, обрабатываются одним и тем же процессом брокера сообщений. Эта архитектура может ограничить общую пропускную способность очереди сообщений. Тем не менее, вы также можете разбивать очередь или тему при ее создании. Вы делаете это, устанавливая для свойства EnablePartitioning для описания очереди или темы значение true .
Секционированная очередь или тема разделена на несколько фрагментов, каждый из которых поддерживается отдельным хранилищем сообщений и брокером сообщений. Service Bus берет на себя ответственность за создание и управление этими фрагментами. Когда приложение отправляет сообщение в секционированную очередь или тему, служебная шина назначает сообщение фрагменту для этой очереди или темы. Когда приложение получает сообщение из очереди или подписки, служебная шина проверяет каждый фрагмент для следующего доступного сообщения, а затем передает его в приложение для обработки.
Эта структура помогает распределить нагрузку между брокерами сообщений и хранилищами сообщений, увеличивая масштабируемость и улучшая доступность. Если брокер сообщений или хранилище сообщений для одного фрагмента временно недоступен, служебная шина может извлекать сообщения из одного из оставшихся доступных фрагментов.
Service Bus назначает сообщение фрагменту следующим образом:
- Если сообщение принадлежит сеансу, все сообщения с тем же значением для свойства * SessionId * отправляются в один и тот же фрагмент.
- Если сообщение не принадлежит сеансу, но отправитель указал значение для свойства PartitionKey , то все сообщения с тем же значением PartitionKey отправляются в один и тот же фрагмент.
Заметка
Если оба свойства SessionId и PartitionKey указаны, то они должны быть установлены на одно значение или сообщение будет отклонено.
- Если свойства SessionId и PartitionKey для сообщения не указаны, но обнаружение дубликатов включено, будет использоваться свойство MessageId . Все сообщения с тем же MessageId будут направлены на один и тот же фрагмент.
- Если сообщения не включают свойство SessionId, PartitionKey или MessageId , тогда служебная шина последовательно назначает сообщения фрагментам. Если фрагмент недоступен, служебная шина перейдет к следующему. Это означает, что временная ошибка в инфраструктуре обмена сообщениями не приводит к сбою операции отправки сообщений.
При принятии решения о том, следует ли или как разбить очередь сообщений или тему сообщения службы шины, рассмотрите следующие моменты:
- Очереди и темы служебной шины создаются в рамках пространства имен служебной шины. В настоящее время служебная шина поддерживает до 100 секционированных очередей или тем в пространстве имен.
- Each Service Bus namespace imposes quotas on the available resources, such as the number of subscriptions per topic, the number of concurrent send and receive requests per second, and the maximum number of concurrent connections that can be established. These quotas are documented on the Microsoft website on the page Service Bus quotas. If you expect to exceed these values, then create additional namespaces with their own queues and topics, and spread the work across these namespaces. For example, in a global application, create separate namespaces in each region and configure application instances to use the queues and topics in the nearest namespace.
- Сообщения, которые отправляются как часть транзакции, должны указывать ключ раздела. Это может быть свойство SessionId , PartitionKey или MessageId . Все сообщения, отправленные как часть одной и той же транзакции, должны указывать один и тот же ключ раздела, поскольку они должны обрабатываться одним и тем же процессом посредника сообщений. Вы не можете отправлять сообщения в разные очереди или темы одной транзакции.
- Разделенные очереди и темы не могут быть настроены для автоматического удаления, когда они простаивают.
- В настоящее время разделенные очереди и темы не могут использоваться с расширенным протоколом очереди сообщений (AMQP), если вы создаете кросс-платформенные или гибридные решения.
Стратегии разделения для API DocumentDB
Azure Cosmos DB — это база данных NoSQL, которая может хранить документы с использованием API DocumentDB . Документ в базе данных базы данных Cosmos DB представляет собой сериализованное JSON представление объекта или другой части данных. Никакие фиксированные схемы не применяются, за исключением того, что каждый документ должен содержать уникальный идентификатор.
Документы организованы в коллекции. Вы можете группировать связанные документы вместе в коллекции. Например, в системе, поддерживающей ведение блога, вы можете хранить содержимое каждого сообщения в блоге в виде документа в коллекции. Вы также можете создавать коллекции для каждого типа объекта. Альтернативно, в многопользовательском приложении, таком как система, в которой разные авторы контролируют и управляют своими сообщениями в блоге, вы можете разделить блоги по авторам и создавать отдельные коллекции для каждого автора. Объем памяти, выделяемый коллекциям, является эластичным и может сокращаться или увеличиваться по мере необходимости.
Коллекции документов обеспечивают естественный механизм для разделения данных в одной базе данных. База данных Cosmos DB внутри страны может охватывать несколько серверов и может попытаться распространить нагрузку, распределяя коллекции по серверам. Самый простой способ реализовать очертание — создать коллекцию для каждого осколка.
Заметка
Каждая база данных Cosmos DB имеет уровень производительности, который определяет объем ресурсов, которые он получает. Уровень производительности связан с лимитом ставки единицы запроса (RU). Предел скорости RU указывает объем ресурсов, зарезервированных и доступных для исключительного использования этой коллекцией. Стоимость коллекции зависит от уровня производительности, выбранного для этой коллекции. Чем выше уровень производительности (и ограничение скорости RU), тем выше заряд. Вы можете настроить уровень производительности коллекции, используя портал Azure. Для получения дополнительной информации см. Страницу [Уровни производительности в базе данных Cosmos] на веб-сайте Microsoft.
Все базы данных создаются в контексте базы данных базы данных базы данных Cosmos. Одна учетная запись может содержать несколько баз данных, и она определяет, в каких регионах создаются базы данных. Каждая учетная запись также обеспечивает собственный контроль доступа. Вы можете использовать учетные записи Cosmos DB для геолокации локаций (коллекции в базах данных) рядом с пользователями, которым необходимо получить к ним доступ, и применять ограничения, чтобы только те пользователи могли подключаться к ним.
Каждая учетная запись Cosmos DB имеет квоту, которая ограничивает количество баз данных и коллекций, которые она может содержать, и объем доступного хранилища документов. Дополнительную информацию см. В разделе « Доступ к подписке и лимиты», «Квоты и ограничения» . Теоретически возможно, что если вы реализуете систему, в которой все осколки принадлежат одной и той же базе данных, вы можете достигнуть предела емкости хранилища.
В этом случае вам может потребоваться создать дополнительные учетные записи и базы данных, а также распространить их на эти базы данных. Однако даже если вы вряд ли достигнете емкости хранилища базы данных, рекомендуется использовать несколько баз данных. Это связано с тем, что каждая база данных имеет собственный набор пользователей и разрешений, и вы можете использовать этот механизм для выделения доступа к коллекциям для каждой базы данных.+
На рисунке 8 показана структура высокого уровня API DocumentDB.
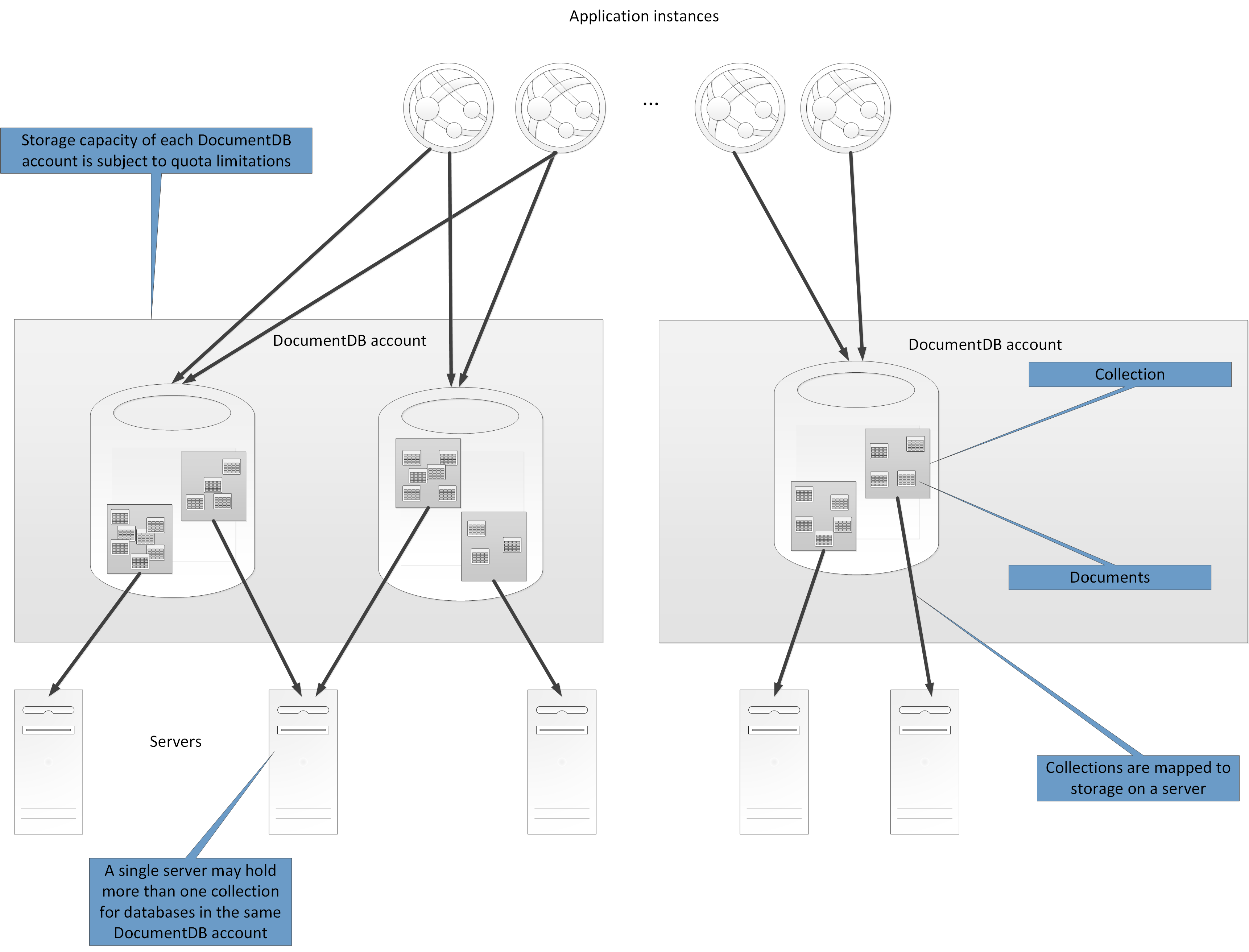
Рисунок 8. Структура архитектуры DocumentDB API
Задача клиентского приложения заключается в том, чтобы направлять запросы на соответствующий осколок, обычно путем реализации собственного механизма отображения, основанного на некоторых атрибутах данных, которые определяют ключ осколка. На рисунке 9 показаны две базы данных API DocumentDB, каждая из которых содержит две коллекции, которые действуют как осколки. Данные заносятся идентификатором арендатора и содержат данные для конкретного арендатора. Базы данных создаются в отдельных учетных записях Cosmos DB. Эти учетные записи расположены в том же регионе, что и арендаторы, для которых они содержат данные. Логика маршрутизации в клиентском приложении использует идентификатор арендатора в качестве ключа осколка.
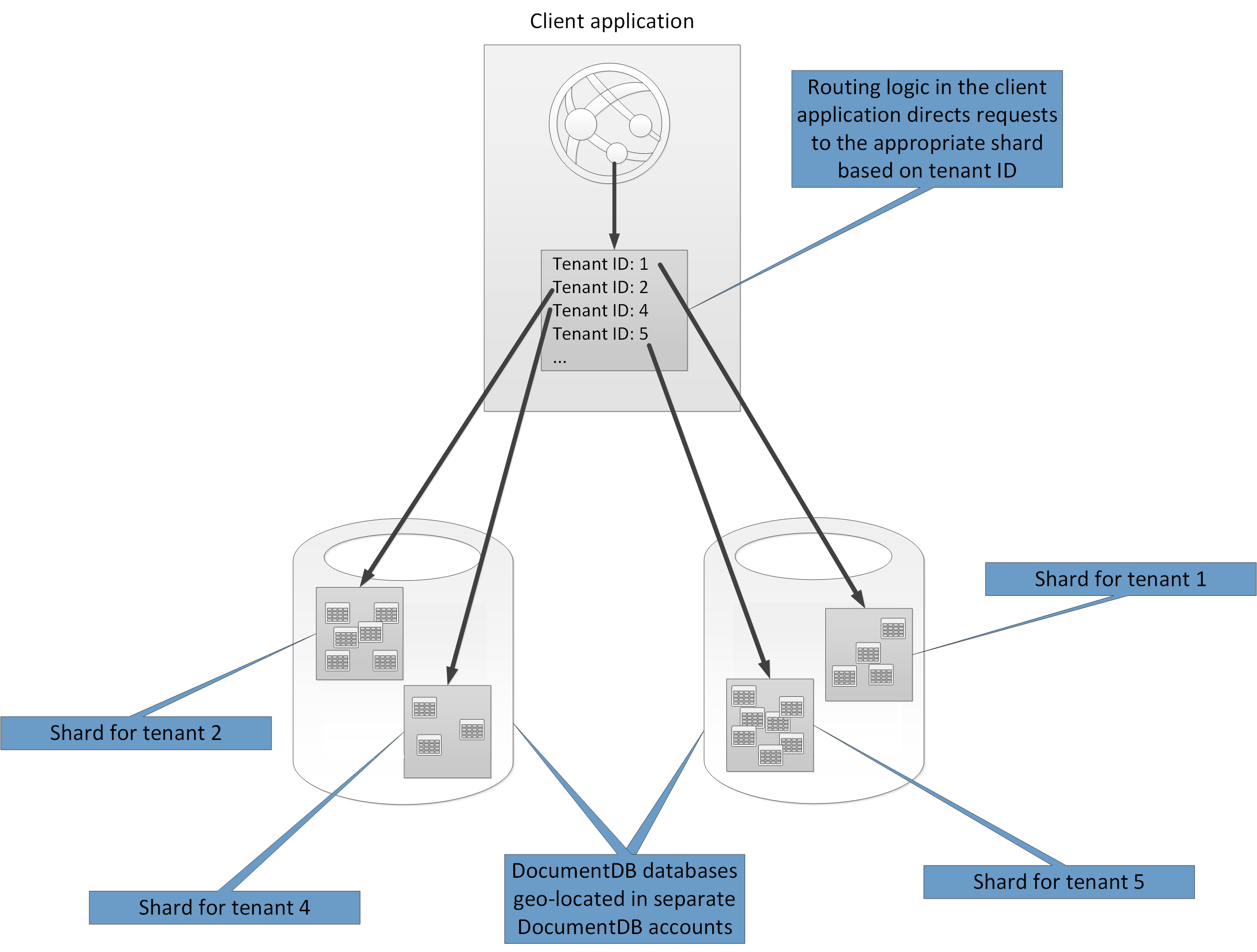
Рисунок 9. Внедрение sharding с использованием API DocumentDB
При принятии решения о разделении данных с помощью DocumentDB API рассмотрите следующие моменты:
- Ресурсы, доступные для базы данных API DocumentDB, зависят от ограничений квоты учетной записи . Каждая база данных может содержать несколько коллекций (опять же, есть предел), и каждая коллекция связана с уровнем производительности, который регулирует ограничение скорости RU (зарезервированная пропускная способность) для этой коллекции. Для получения дополнительной информации см. [Лайт-подписка и лимиты обслуживания, квоты и ограничения].
- Каждый документ должен иметь атрибут, который может использоваться для уникальной идентификации этого документа в коллекции, в которой он хранится . Этот атрибут отличается от ключа осколка, который определяет, какая коллекция содержит документ. Коллекция может содержать большое количество документов. Теоретически, он ограничен только максимальной длиной идентификатора документа. Идентификатор документа может содержать до 255 символов.
- Все операции с документом выполняются в контексте транзакции. Транзакции привязаны к коллекции, в которой содержится документ. Если операция завершается неудачно, выполняемая работа выполняется откат. Хотя документ подлежит операции, любые сделанные изменения подвергаются изоляции на основе моментального снимка. Этот механизм гарантирует, что если, например, запрос на создание нового документа не удастся, другой пользователь, который запрашивает базу данных одновременно, не увидит частичный документ, который затем будет удален.
- Запросы базы данных также привязаны к уровню сбора . Один запрос может извлекать данные только из одной коллекции. Если вам нужно получить данные из нескольких коллекций, вы должны запросить каждую коллекцию отдельно и объединить результаты в код приложения.
- Базы данных DocumentDB API поддерживают программируемые элементы, которые могут быть сохранены в коллекции вместе с документами, К ним относятся хранимые процедуры, пользовательские функции и триггеры (написанные на JavaScript). Эти элементы могут получить доступ к любому документу внутри той же коллекции. Кроме того, эти элементы выполняются либо внутри области внешней транзакции (в случае триггера, который срабатывает в результате операции создания, удаления или замены, выполняемой в отношении документа), либо путем запуска новой транзакции (в случае хранимой процедуры, которая запускается в результате явного запроса клиента). Если код в программируемом элементе генерирует исключение, транзакция откатывается. Вы можете использовать хранимые процедуры и триггеры для поддержания целостности и согласованности между документами, но эти документы должны быть частью одной коллекции.
- Коллекции, которые вы намерены хранить в базах данных, вряд ли превысят пределы пропускной способности, определяемые уровнями производительности коллекций . Для получения дополнительной информации см. Раздел «Запросить единицы измерения в Azure Cosmos DB] cosmos-db-ru . Если вы ожидаете достижения этих ограничений, рассмотрите разделение коллекций между базами данных в разных учетных записях, чтобы уменьшить нагрузку на коллекцию.
Стратегии разделения на Azure Search
Возможность поиска данных часто является основным методом навигации и исследований, который предоставляется многими веб-приложениями. Это помогает пользователям быстро находить ресурсы (например, продукты в приложении для электронной коммерции) на основе сочетаний критериев поиска. Служба поиска Azure предоставляет возможности полнотекстового поиска по веб-контенту и включает такие функции, как тип-вперед, предлагаемые запросы, основанные на близких совпадениях, и фасетная навигация. Полное описание этих возможностей доступно на странице Что такое Azure Search? на веб-сайте Microsoft.
Azure Search хранит контент, доступный для поиска, как документы JSON в базе данных. Вы определяете индексы, которые определяют поля, доступные для поиска, в этих документах и предоставляют эти определения для Azure Search. Когда пользователь отправляет запрос на поиск, Azure Search использует соответствующие индексы для поиска соответствующих элементов.
Чтобы уменьшить конфликт, хранилище, которое используется Azure Search, можно разделить на 1, 2, 3, 4, 6 или 12 разделов, и каждый раздел может быть реплицирован до 6 раз. Произведение числа разделов, умноженное на количество реплик, называется поисковой единицей (SU). Один экземпляр Azure Search может содержать максимум 36 SU (база данных с 12 разделами поддерживает максимум 3 реплики).
Вы получаете счет за каждый SU, выделенный для вашего сервиса. По мере увеличения объема поискового контента или увеличения количества запросов поиска вы можете добавить SU к существующему экземпляру Azure Search для обработки дополнительной нагрузки. Azure Search сам распределяет документы равномерно по разделам. В настоящее время не поддерживаются стратегии ручного разделения.
Каждый раздел может содержать максимум 15 миллионов документов или занимать 300 ГБ места для хранения (в зависимости от того, что меньше). Вы можете создать до 50 индексов. Производительность службы варьируется и зависит от сложности документов, доступных индексов и последствий задержки сети. В среднем, одна реплика (1 SU) должна иметь возможность обрабатывать 15 запросов в секунду (QPS), хотя мы рекомендуем выполнять бенчмаркинг с вашими собственными данными, чтобы получить более точный показатель пропускной способности. Для получения дополнительной информации см. Страницу « Ограничения обслуживания» в Azure Search на веб-сайте Microsoft.
Заметка
Вы можете хранить ограниченный набор типов данных в документах, доступных для поиска, включая строки, логические, числовые данные, данные о времени и некоторых географических данных. Для получения дополнительной информации см. Страницу Поддерживаемые типы данных (Azure Search)на веб-сайте Microsoft.
У вас ограниченный контроль над тем, как Azure Search разделяет данные для каждого экземпляра службы. Тем не менее, в глобальной среде вы можете повысить производительность и сократить время ожидания и конкуренции за счет разделения самой службы с использованием любой из следующих стратегий:
- Создайте экземпляр Azure Search в каждом географическом регионе и убедитесь, что клиентские приложения направлены в ближайший доступный экземпляр. Эта стратегия требует, чтобы любые обновления для поиска контента были своевременно реплицированы во всех экземплярах службы.
- Создайте два уровня Azure Search:
- Локальная служба в каждом регионе, которая содержит данные, наиболее часто используемые пользователями в этом регионе. Пользователи могут направлять запросы здесь для быстрых, но ограниченных результатов.
- Глобальная служба, которая охватывает все данные. Пользователи могут направлять запросы здесь для более медленных, но более полных результатов.
Этот подход наиболее подходит, когда существует значительная региональная вариация в данных, которые проходят поиск.
Стратегии разделения для кеша лазурного редиса
Кэш Azure Redis обеспечивает общую службу кэширования в облаке, основанную на хранилище данных ключа Redis. Как следует из названия, Azure Redis Cache предназначен как кэширующее решение. Используйте его только для хранения временных данных, а не для постоянного хранилища данных. Приложения, использующие кэш Azure Redis, должны продолжать работать, если кеш недоступен. Azure Redis Cache поддерживает первичную / вторичную репликацию для обеспечения высокой доступности, но в настоящее время ограничивает максимальный размер кэша до 53 ГБ. Если вам нужно больше места, чем это, вы должны создать дополнительные кеши. Для получения дополнительной информации перейдите на страницу Azure Redis Cache на веб-сайте Microsoft.
Разделение хранилища данных Redis включает разделение данных между экземплярами службы Redis. Каждый экземпляр представляет собой один раздел. Azure Redis Cache абстрагирует услуги Redis за фасадом и не раскрывает их напрямую. Простейшим способом реализации секционирования является создание нескольких экземпляров кэша Azure Redis и распространение данных по ним.
Вы можете связать каждый элемент данных с идентификатором (ключ раздела), который указывает, в каком кеше хранится элемент данных. Логика клиентского приложения может затем использовать этот идентификатор для маршрутизации запросов к соответствующему разделу. Эта схема очень проста, но при изменении схемы разделения (например, при создании дополнительных экземпляров кэша Azure Redis) клиентские приложения могут нуждаться в переконфигурации.
Нативный Redis (не Azure Redis Cache) поддерживает разделение на стороне сервера на основе кластера Redis. В этом подходе вы можете равномерно распределить данные по серверам с помощью механизма хэширования. Каждый сервер Redis хранит метаданные, которые описывают диапазон хеш-ключей, которые хранятся в разделе, а также содержит информацию о том, какие хеш-ключи находятся в разделах на других серверах.
Клиентские приложения просто отправляют запросы на любой из участвующих серверов Redis (возможно, самый близкий). Сервер Redis проверяет клиентский запрос. Если он может быть разрешен локально, он выполняет запрошенную операцию. В противном случае он перенаправляет запрос на соответствующий сервер.
Эта модель реализована с использованием кластера Redis и более подробно описана на странице учебника кластера Redis на веб-сайте Redis. Кластеризация Redis прозрачна для клиентских приложений. Дополнительные серверы Redis могут быть добавлены в кластер (и данные могут быть переразделены), не требуя перенастройки клиентов.
Важный
Кэш Azure Redis в настоящее время не поддерживает кластер Redis. Если вы хотите реализовать этот подход с помощью Azure, вы должны реализовать свои собственные серверы Redis, установив Redis на набор виртуальных машин Azure и настроив их вручную. На странице Запуск Redis на виртуальной машине CentOS Linux в Azure на веб-сайте Microsoft представлен пример, показывающий, как создавать и настраивать узел Redis, работающий как Azure VM.
Раздел «Разделение страницы : как разделить данные между несколькими экземплярами Redis на веб-сайте Redis предоставляет дополнительную информацию о реализации разделения с помощью Redis. В оставшейся части этого раздела предполагается, что вы выполняете разделение на стороне клиента или прокси.
При принятии решения о разделении данных с помощью кэша Azure Redis рассмотрите следующие моменты:
- Кэш Azure Redis не предназначен для работы в качестве постоянного хранилища данных, поэтому, независимо от схемы разбиения на разделы, ваш код приложения должен иметь возможность извлекать данные из местоположения, которое не является кешем.
- Данные, к которым часто обращаются вместе, должны храниться в одном разделе. Redis — это мощное хранилище ключей, которое предоставляет несколько высоко оптимизированных механизмов структурирования данных. Эти механизмы могут быть следующими:
- Простые строки (двоичные данные длиной до 512 МБ)
- Совокупные типы, такие как списки (которые могут действовать как очереди и стеки)
- Наборы (упорядоченные и неупорядоченные)
- Хеши (которые могут группировать связанные поля вместе, например, элементы, представляющие поля в объекте)
- Совокупные типы позволяют связать многие связанные значения с одним и тем же ключом. Ключ Redis идентифицирует список, набор или хеш, а не элементы данных, которые он содержит. Все эти типы доступны с помощью кэша Azure Redis и описываются типами данныхна веб-сайте Redis. Например, в части системы электронной торговли, которая отслеживает заказы, которые размещаются клиентами, сведения о каждом клиенте могут храниться в хеше Redis, который вводится с помощью идентификатора клиента. Каждый хэш может содержать коллекцию идентификаторов заказов для клиента. Отдельный набор Redis может содержать заказы, снова структурированные как хэши и с помощью идентификатора заказа. На рисунке 10 показана эта структура. Обратите внимание, что Redis не реализует никакой формы ссылочной целостности, поэтому ответственность разработчика заключается в поддержании отношений между клиентами и заказами.
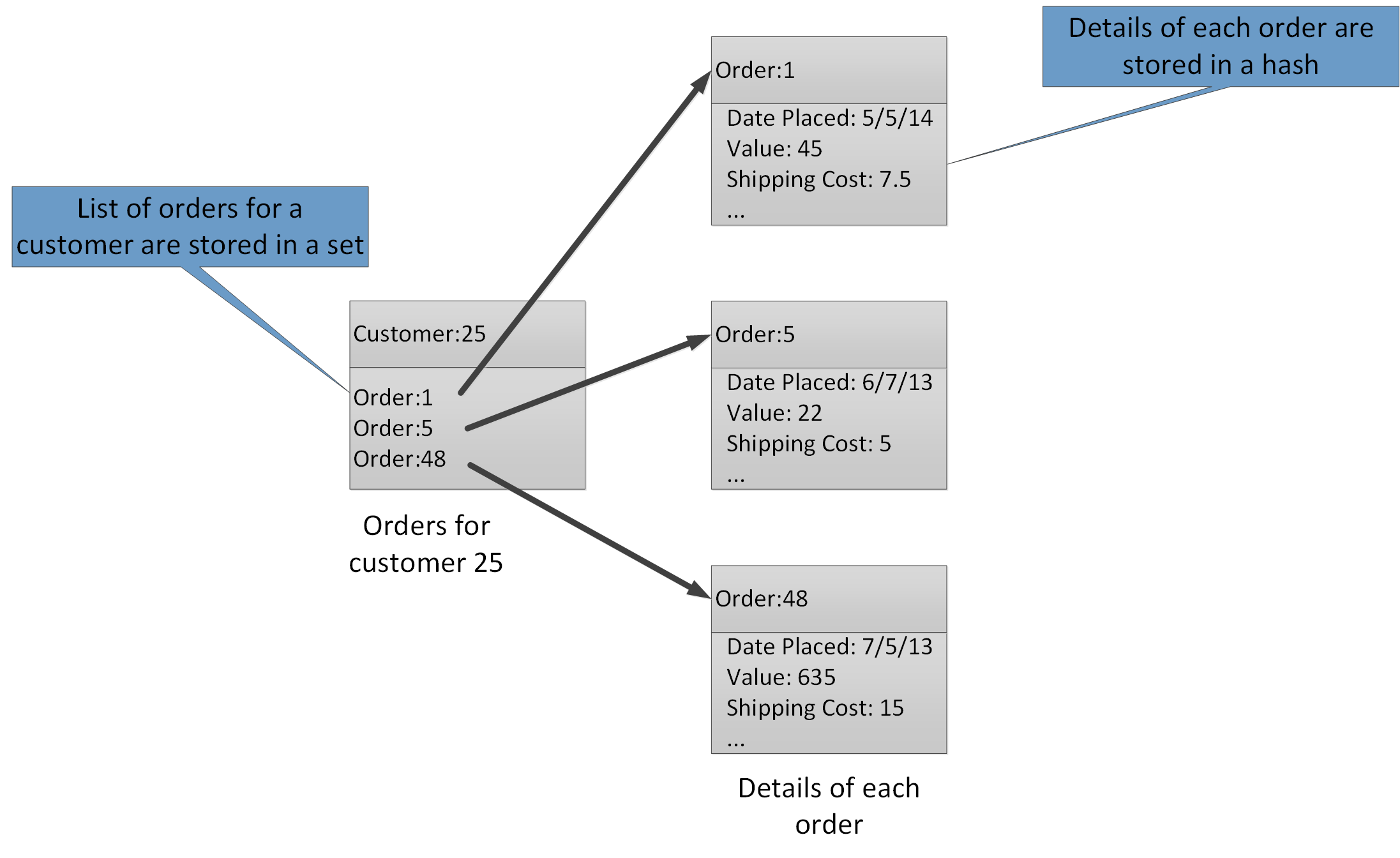
Рисунок 10. Предлагаемая структура в хранилище Redis для записи заказов клиентов и их деталей
Заметка
В Redis все ключи представляют собой двоичные данные (например, строки Redis) и могут содержать до 512 МБ данных. Теоретически ключ может содержать практически любую информацию. Тем не менее, мы рекомендуем принять согласованное соглашение об именах для ключей, которые описывают тип данных и идентифицируют объект, но не слишком длинны. Общий подход заключается в использовании ключей формы «entity_type: ID». Например, вы можете использовать «клиент: 99», чтобы указать ключ для клиента с идентификатором 99.
- Вы можете реализовать вертикальное разбиение на разделы путем хранения связанной информации в разных агрегатах в одной базе данных. Например, в приложении электронной коммерции вы можете хранить обычно доступную информацию о продуктах в одном хэше Redis и менее часто используемую подробную информацию в другой. Оба хэша могут использовать один и тот же идентификатор продукта как часть ключа. Например, вы можете использовать «продукт: nn » (где nn — идентификатор продукта) для информации о продукте и «product_details: nn » для подробных данных. Эта стратегия может помочь уменьшить объем данных, которые, скорее всего, будут запрашивать большинство запросов.
- Вы можете переделать хранилище данных Redis, но имейте в виду, что это сложная и трудоемкая задача. Кластеризация Redis может автоматически перераспределять данные, но эта возможность недоступна с помощью кэша Azure Redis. Поэтому, когда вы разрабатываете схему разбиения, попробуйте оставить достаточное свободное пространство в каждом разделе, чтобы обеспечить ожидаемый рост данных с течением времени. Однако помните, что кэш Azure Redis предназначен для временного кэширования данных, а данные, хранящиеся в кеше, могут иметь ограниченный срок службы, указанный как значение времени жизни (TTL). Для относительно изменчивых данных TTL может быть коротким, но для статических данных TTL может быть намного длиннее. Избегайте хранения больших объемов долговременных данных в кеше, если объем этих данных, вероятно, заполнит кеш.
Заметка
При использовании кеша Azure Redis вы указываете максимальный размер кеша (от 250 МБ до 53 ГБ), выбирая соответствующий уровень цен. Однако после создания кэша Azure Redis вы не можете увеличить (или уменьшить) его размер.
- Пакеты Redis и транзакции не могут охватывать несколько подключений, поэтому все данные, на которые влияет пакет или транзакция, должны храниться в одной и той же базе данных (осколок).
Заметка
Последовательность операций в транзакции Redis не обязательно является атомарной. Команды, которые составляют транзакцию, проверяются и ставятся в очередь перед их запуском. Если во время этой фазы возникает ошибка, вся очередь отбрасывается. Однако после успешной отправки транзакции очереди выполняются последовательно. Если какая-либо команда выходит из строя, только эта команда перестает работать. Выполняются все предыдущие и последующие команды в очереди. Для получения дополнительной информации перейдите на страницу « Транзакции» на веб-сайте Redis.
- Redis поддерживает ограниченное число атомных операций. Единственными операциями этого типа, которые поддерживают несколько ключей и значений, являются операции MGET и MSET. Операции MGET возвращают коллекцию значений для указанного списка ключей, а операции MSET хранят коллекцию значений для указанного списка ключей. Если вам нужно использовать эти операции, пары ключ-значение, на которые ссылаются команды MSET и MGET, должны храниться в одной базе данных.
Стратегии разделения для лазурной службы
Azure Service Fabric — это платформа микросервисов, которая обеспечивает среду выполнения для распределенных приложений в облаке. Service Fabric поддерживает .Net гостевые исполняемые файлы, службы с сохранением состояния и без состояния и контейнеры. Службы с учетом состояния предоставляют надежную коллекцию для постоянного хранения данных в коллекции значений ключей в кластере Service Fabric. Для получения дополнительной информации о стратегиях для частичных ключей в надежной коллекции см. Рекомендации и рекомендации для надежных коллекций в Azure Service Fabric .
Больше информации
- Обзор Azure Service Fabric представляет собой введение в Azure Service Fabric.
- Служба надежных сервисов разделов предоставляет более подробную информацию о надежных услугах в Azure Service Fabric.
Стратегии разделения для концентраторов событий Azure
Azure Event Hubs предназначен для потоковой передачи данных в массовом масштабе, а разбиение встроено в сервис, чтобы обеспечить горизонтальное масштабирование. Каждый потребитель только считывает определенный раздел потока сообщений.
Издатель событий знает только свой ключ раздела, а не раздел, на который публикуются события. Эта развязка ключа и раздела изолирует отправителя от необходимости слишком много знать о последующей обработке. (Также возможно отправлять события непосредственно в данный раздел, но обычно это не рекомендуется).
При выборе количества разделов учитывайте долгосрочную шкалу. После создания концентратора событий вы не можете изменить количество разделов.
Дополнительные сведения об использовании разделов в концентраторах событий см. В разделе Что такое концентраторы событий? ,
Сведения о компромиссах между доступностью и согласованностью см. В разделе Доступность и согласованность в концентраторах событий .
Перебалансировка разделов
По мере того как система созревает и вы лучше понимаете шаблоны использования, вам, возможно, придется настроить схему разбиения. Например, отдельные разделы могут начать привлекать непропорциональный объем трафика и стать горячим, что приведет к чрезмерному соперничеству. Кроме того, возможно, вы недооценили объем данных в некоторых разделах, заставив вас приблизиться к ограничениям емкости хранилища в этих разделах. Независимо от причины, иногда необходимо перебалансировать разделы для более равномерного распределения нагрузки.
В некоторых случаях системы хранения данных, которые публично не раскрывают, как данные распределяются серверам, могут автоматически перебалансировать разделы в пределах доступных ресурсов. В других ситуациях перебалансировка — это административная задача, состоящая из двух этапов:
- Определение новой стратегии разделения для определения:
- Какие разделы могут быть разделены (или, возможно, объединены).
- Как распределить данные для этих новых разделов, создав новые ключи разделов.
- Перенос затронутых данных из старой схемы разбиения на новый набор разделов.
Заметка
Отображение коллекций баз данных на серверах является прозрачным, но вы все равно можете достичь емкости хранилища и пропускной способности учетной записи Cosmos DB. В этом случае вам может потребоваться перепроектировать схему разбиения и перенести данные.
В зависимости от технологии хранения данных и дизайна вашей системы хранения данных вы можете переносить данные между разделами во время их использования (онлайн-миграция). Если это невозможно, вам может потребоваться временно отключить затронутые разделы при перемещении данных (автономная миграция).
Внедрение
Автономная миграция, возможно, является самым простым подходом, поскольку она снижает вероятность возникновения конкуренции. Не вносите никаких изменений в данные во время их перемещения и реструктуризации.
Концептуально этот процесс включает следующие этапы:
- Отметьте осколок в автономном режиме.
- Сплит-слияние и перенос данных в новые осколки.
- Проверьте данные.
- Принесите новые осколки в Интернете.
- Удалите старый осколок.
Чтобы сохранить некоторую доступность, вы можете пометить исходный осколок как только для чтения на шаге 1, а не сделать его недоступным. Это позволяет приложениям считывать данные во время их перемещения, но не изменять их.
Онлайн-миграция
Онлайн-миграция более сложна для выполнения, но менее разрушительна для пользователей, поскольку данные остаются доступными в течение всей процедуры. Этот процесс аналогичен процессу автономной миграции, за исключением того, что исходный осколок не отмечен в автономном режиме (шаг 1). В зависимости от детализации процесса миграции (например, будь то элемент по элементу или осколку путем осколка) код доступа к данным в клиентских приложениях может обрабатывать данные чтения и записи, которые хранятся в двух местах (исходный осколок и новый осколок).
Пример решения, поддерживающего онлайновую миграцию, приведен в статье « Масштабирование» с помощью инструмента «Сплит-слияния» с помощью Elastic Database на веб-сайте Microsoft.
Связанные шаблоны и руководство
При рассмотрении стратегий обеспечения согласованности данных следующие шаблоны могут также иметь отношение к вашему сценарию:
- Страница праймера согласования данных на веб-сайте Microsoft описывает стратегии обеспечения согласованности в распределенной среде, такой как облако.
- На странице руководства по разделению данных на веб-сайте Microsoft представлен общий обзор того, как создавать разделы для соответствия различным критериям в распределенном решении.
- Модель Sharding , как описано на веб — сайте Microsoft суммирует некоторые общие стратегии сегментирование данных.
- Рисунок индекс таблицы , как описано на веб — сайте Microsoft показывает , как создать вторичные индексы над данными. Приложение может быстро извлекать данные с помощью этого подхода, используя запросы, которые не ссылаются на первичный ключ коллекции.
- Материализовался шаблон вид , как описано на веб — сайте Microsoft описывает , как создавать предварительно заполненные представления , которые обобщают данные для поддержки быстрых операций запроса. Этот подход может быть полезен в хранилище секционированных данных, если разделы, содержащие данные, суммируемые, распределяются между несколькими сайтами.
- Статья « Использование сети доставки контента Azure» на веб-сайте Microsoft предоставляет дополнительные рекомендации по настройке и использованию сети доставки контента с помощью Azure.
Больше информации
- Страница Что такое база данных Azure SQL? на веб-сайте Microsoft представлена подробная документация, описывающая, как создавать и использовать базы данных SQL.
- Обзор страницы « Упругие базы данных» на веб-сайте Microsoft содержит подробное введение в Elastic Database.
- Масштабирование страницы с помощью инструмента сплит-слияния с использованием эластичной базы данных на веб -узлеMicrosoft содержит информацию об использовании службы split-merge для управления обломами Elastic Database.
- Страница Azure масштабируемость хранения и целевые показатели на веб — сайте Microsoft документирует текущие проклейки и пропускной способности пределы Azure Storage.
- Страница Выполнение транзакций группы лиц на веб-сайте Microsoft предоставляет подробную информацию об осуществлении транзакционных операций над объектами, которые хранятся в хранилище таблиц Azure.
- В статье « Руководство по дизайну таблицы хранилища Azure» на веб-сайте Microsoft содержится подробная информация о разделении данных в хранилище таблиц Azure.
- На странице Использование сети доставки контента Azure на веб-узле Microsoft описано, как реплицировать данные, хранящиеся в хранилище данных Azure, используя сеть доставки контента Azure.
- Страница Что такое Azure Search? на веб-сайте Microsoft предоставляет полное описание возможностей, доступных в Azure Search.
- Лимит страниц в Azure Search на веб-сайте Microsoft содержит информацию о возможностях каждого экземпляра Azure Search.
- Страница Поддерживаемые типы данных (Azure Search) на веб-сайте Microsoft суммируют типы данных, которые можно использовать в документах и индексах, доступных для поиска.
- На странице Azure Redis Cache на веб — сайте Microsoft обеспечивает введение в Azure Redis Cache.
- Перегородки: как разделить данные между несколькими экземплярами Redis страницы на веб — сайте Redis предоставляет информацию о том , как осуществить разделение с Redis.
- На странице Запуск Redis на VMware CentOS Linux в Azure на веб-сайте Microsoft представлен пример, показывающий, как создавать и настраивать узел Redis, работающий как Azure VM.
- На странице « Типы данных» на веб-сайте Redis описаны типы данных, доступные с помощью Redis и Azure Redis Cache.
Original(english): https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning
Translation: Basic, need improvement
Status: Draft
Action: Vote to improve